
La manipulation des fichiers texte
Contenu de la page
8. La manipulation des fichiers texte
L’objectif de ce chapitre est d’expliquer comment s’effectue, en langage Python, la lecture et l’écriture de données dans des fichiers. Seul le cas des fichiers de texte est abordé.
8.1. Généralités sur l’utilisation de fichiers en programmation
8.1.1. Pourquoi utiliser des fichiers ?
Jusqu’à présent, les données que nous avons traitées dans des programmes étaient :
stockées dans des variables (simples ou structurées) grâce à des affectations, directement dans le code source
saisies au clavier puis stockées dans des variables au cours de l’exécution.
Ces deux méthodes sont très limitées et inadaptées pour traiter de grandes quantités de données. Prenons l’exemple d’un programme calculant la moyenne obtenue par 1500 élèves à un contrôle de maths. Il n’est pas raisonnable de saisir au clavier les 1500 notes. En supposant qu’on puisse tout de même le faire, cela signifie que si le nombre de valeurs change il faudra modifier le code source du programme. Or, un programme bien conçu doit être indépendant des données qu’il traite. La quantité de données ainsi que leurs valeurs doivent pouvoir changer sans qu’on ait besoin de modifier le programme.
Jusqu’à présent également, les résultats produits par nos programmes étaient simplement affichés à l’écran. Or, les résultats produits sont souvent trop volumineux pour être simplement affichés. Ils ont aussi parfois besoin d’être conservés, ce que ne permet pas l’affichage à l’écran.
L’intérêt des fichiers est de bien séparer les programmes des données qu’ils traitent et des résultats qu’ils produisent. L’utilisation de fichiers permet de stocker dans des fichiers séparés :
le programme source
les données à traiter, c’est-à-dire les entrées ou le fichier d’entrées
les données produites, c’est-à-dire les sorties ou le fichier de sorties.
Si on prend l’exemple d’un programme calculant les moyennes obtenues par des étudiants à trois examens (cf. figure ci-dessous), le fichier d’entrées contient la liste des étudiants, avec pour chacun les trois notes obtenues. Le fichier de sorties contient la même liste d’étudiants, avec pour chacun la moyenne obtenue.
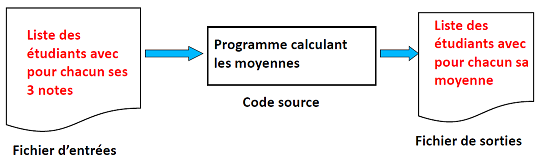
Programme utilisant des fichiers
La seule contrainte imposée par l’utilisation de fichiers pour les entrées et les sorties est la définition précise et sans ambiguïté de la syntaxe (i.e., le format) de ces fichiers. Cette définition de la syntaxe doit précéder l’écriture du programme source, qui doit en tenir compte. Dans notre exemple, une syntaxe possible pour le fichier d’entrées est montrée sur la figure suivante. Dans cette syntaxe, chaque ligne contient les caractéristiques d’un étudiant(e) séparées par des virgules : nom, prénom, note obtenue au 1er examen, note obtenue au 2e examen, note obtenue au 3e examen.

Syntaxe du fichier d’entrées
Le fichier de sorties peut reprendre la même syntaxe que le fichier d’entrées, à ceci près que les 3 notes sont remplacées par la moyenne.
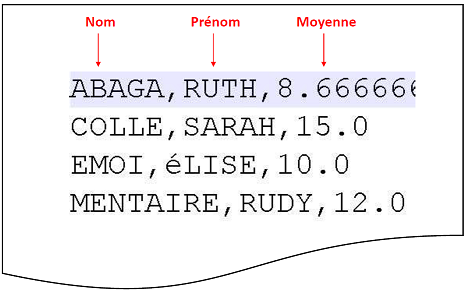
Syntaxe du fichier de sorties
Il existe principalement deux types de fichiers :
les fichiers texte
les fichiers binaires.
8.1.2. Les fichiers texte
8.1.2.1. Contenu
Comme son nom l’indique, un fichier texte contient des données textuelles, lisibles grâce à l’utilisation d’un éditeur de texte tel que Notepad++, Bloc-notes, Xemacs ou Sublime Text. Ces données textuelles peuvent être :
des caractères imprimables : lettres, chiffres, ponctuation, symboles, etc
des espaces
des caractères de fin de paragraphe ou de fin de ligne.
Tous les programmes sources, quel que soit le langage utilisé, sont mémorisés dans des fichiers texte. Un fichier texte peut également être utilisé pour conserver des données textuelles brutes, c’est-à-dire sans aucune mise en forme.
8.1.2.2. Notion d’encodage
Dans la mémoire vive d’un ordinateur ou sur un support de stockage tel qu’un disque dur, toutes les données, quels que soient leurs types, sont codées à l’aide d’un langage binaire, dont l’alphabet se compose de deux symboles uniquement : 0 et 1. Chaque caractère d’un fichier texte est donc mémorisé à l’aide d’une suite de bits, c’est-à-dire une suite de chiffres dont la valeur est 0 ou 1. La suite de bits représentant un caractère dépend de l’encodage utilisé. En informatique, un encodage est un processus permettant de traduire un caractère en une suite plus ou moins longue de bits qui correspond à sa représentation binaire. Il existe de nombreux encodages, parmi lesquels nous pouvons citer les plus couramment utilisés :
ASCII : un des premiers encodages utilisés en informatique. Il n’est quasiment plus utilisé aujourd’hui car il ne permet l’encodage que de 128 caractères différents.
ISO-8859-1 ou ANSI : encodage dit « occidental » permettant de coder tous les caractères latins.
UTF-8 : encodage le plus répandu depuis 2016. Il permet de coder de nombreux caractères issus de nombreux alphabets (latin, arabe, cyrillique, etc).
Le tableau suivant montre les représentations binaires des caractères « e » et « é » avec les trois encodages cités ci-dessus.
Caractère |
ASCII |
ANSI |
UTF-8 |
|---|---|---|---|
e |
01100101 |
01100101 |
01100101 |
é |
non défini |
11101001 |
11000011 |
Nous pouvons remarquer que la représentation binaire de « e » est identique dans les trois encodages. En revanche, le « é » ne peut être codé en ASCII. De plus, sa représentation binaire est différente en ANSI et en UTF-8. Ces observations sont identiques pour tous les caractères accentués.
Lorsqu’on travaille avec un fichier texte, il est primordial de savoir avec quel encodage il a été créé. Considérons par exemple un fichier texte utilisant l’encodage ANSI. Le contenu du fichier est le suivant :

Fichier texte initial
Nous envoyons via la messagerie électronique ce fichier à deux amis A et B. Notre ami A récupère le fichier, puis l’ouvre dans son éditeur de texte en utilisant également l’encodage ANSI. Voici ce qui s’affiche sur l’écran de A :
Fichier ouvert avec ANSI
Dans ce cas, tout se passe bien : l’encodage utilisé par A pour lire le fichier est le même que celui avec lequel nous l’avons créé.
Notre ami B récupère également le fichier, mais l’ouvre dans son éditeur en utilisant l’encodage UTF-8. Voici ce qui s’affiche sur l’écran de B :

Fichier ouvert avec UTF-8
Dans ce cas, tous les caractères apparaissent normalement, sauf les caractères accentués ! Ce qui est normal puisque ces caractères ne sont pas codés de la même façon en ANSI et en UTF-8. Leur lecture avec un encodage UTF-8, alors qu’ils ont été mémorisés avec ANSI, ne peut donc pas s’effectuer correctement.
Autre exemple illustrant l’importance de l’encodage pour le traitement des fichiers texte : voici ci-dessous un fichier texte encodé en UTF-8 :

Fichier encodé avec UTF-8
Voici ci-dessous le même fichier ouvert avec un encodage ANSI :

Fichier lu avec ANSI
Tous les caractères accentués ont été mal décodés et apparaissent comme des suites de deux caractères telles que « é » (à la place de « é ») ou « ï » (à la place de « ï »).
L’encodage est donc une information essentielle lorsqu’on traite des fichiers texte. Dans la plupart des langages de programmation, l’encodage est une information qui doit être fournie aux différentes instructions/fonctions/méthodes qui lisent les données contenues dans les fichiers texte. Tous les éditeurs permettent généralement de paramétrer l’encodage utilisé pour créer un fichier, ou de modifier l’encodage d’un fichier existant. Lorsqu’on ne connaît pas l’encodage d’un fichier texte, une bonne méthode est d’ouvrir ce fichier avec un éditeur, et de tester plusieurs encodages jusqu’à obtenir celui avec lequel le contenu du fichier (en particulier les caractères accentués !) est lisible.
8.1.3. Les fichiers binaires
Un fichier binaire est un fichier contenant des données non textuelles qui sont illisibles avec un éditeur de texte. Voici quelques exemples de fichiers binaires :
une image (format, JPEG, GIF, PNG, etc)
un son (format WAV, MP3, etc)
une vidéo (format AVI, MOV, MP4, etc)
un programme exécutable (fichier ayant l’extension .exe)
un document Word, Excel, Libre Office, etc.
La plupart du temps (à l’exception des programmes exécutables), les fichiers binaires sont créés à l’aide de logiciels dédiés (Paint, Gimp, Word, Excel, etc). Seuls ces logiciels dédiés permettent d’en lire les contenus.
Prenons l’exemple d’un fichier contenant une image au format PNG. Lorsqu’on ouvre ce fichier avec le logiciel de traitement d’images Irfanview, l’image s’affiche correctement :
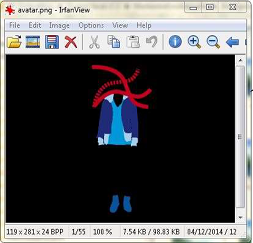
Image lue avec Irfanview
Lorsqu’on essaie d’ouvrir le même fichier avec un éditeur de texte, voici ce qui s’affiche :
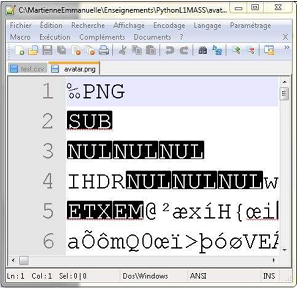
Image lue avec éditeur
Voici ce que donne un diaporama Powerpoint… ouvert avec Powerpoint :
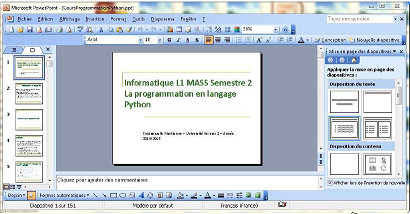
Diaporama lu avec Powerpoint
et ouvert avec un éditeur de texte :
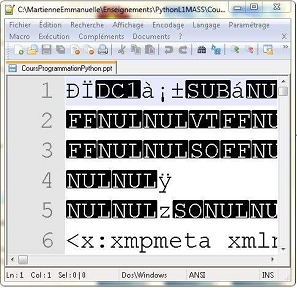
Diaporama lu avec éditeur
8.1.4. Manipulation des fichiers texte : quelles fonctionnalités ?
Dans ce chapitre, nous nous intéresserons à la manipulation des fichiers texte uniquement. Pour pouvoir traiter correctement les fichiers texte, en tant que fichiers d’entrées ou de sorties, les programmes doivent être en mesure :
d’ouvrir un fichier se trouvant sur un support de stockage
de lire tout le contenu d’un fichier
de créer un nouveau fichier
d’écrire des données dans un fichier
de modifier des données se trouvant dans un fichier
de fermer un fichier.
La plupart des langages proposent toutes ces fonctionnalités.
8.2. Manipulation des fichiers texte en Python
Comme vous pourrez le constater dans la suite de cette section, un fichier en Python est considéré comme un objet. Voici donc les principales fonctions et méthodes permettant de traiter des fichiers texte.
8.2.1. Récupération du dossier courant : la fonction getcwd() du module os
Le dossier courant est le dossier dans lequel s’exécute un programme. Ce dossier peut varier d’un environnement de programmation à un autre. Dans PyCharm, lorsqu’on exécute un programme Python, le dossier courant est celui où est stocké le programme. Dans VSCode, le dossier courant est le dossier qui a été ouvert pour travailler (qui n’est pas forcément celui où est stocké le programme qu’on exécute !). La fonction getcwd() permet de connaître le dossier courant dans lequel s’exécute un programme. Elle retourne une chaîne contenant le chemin complet du dossier courant.
import os
courant = os.getcwd()
print(f"Le dossier courant est : {courant}.")
Le dossier courant est : C:\Users\martienne_e.
Lorsqu’un programme traite des fichiers, ceux-ci doivent impérativement être stockés dans le dossier courant.
8.2.2. Modification du dossier courant : la fonction chdir() du module os
Il est possible de modifier le dossier courant avec la fonction chdir(). La syntaxe de cette fonction est la suivante :
os.chdir(chemin)
où chemin est une chaîne contenant le chemin du nouveau dossier
courant (dossier dans lequel doivent impérativement figurer les fichiers
à traiter !!). Ce chemin peut-être :
absolu : il s’agit alors d’un chemin complet dont le point de départ est la racine de l’espace de stockage. Le chemin :
M:\MesDonnées\L1\Python\TD1est un exemple de chemin absolu indiquant l’emplacement complet du dossierTD1sur le disqueM.relatif : il s’agit alors d’un chemin dont le point de départ est le dossier courant. Le chemin :
Info\Bureautiqueest un exemple de chemin relatif indiquant l’emplacement du dossierBureautiqueà partir du dossier courant.
Le programme suivant est un exemple d’utilisation de la fonction
chdir() permettant de paramétrer le dossier
'C:\Users\martienne_e\data' comme nouveau dossier courant.
import os
courant = os.getcwd()
print(f"Le dossier courant est : {courant}")
nouveau = courant + '\data'
os.chdir(nouveau)
courant = os.getcwd()
print(f"Le nouveau dossier courant est : {courant}")
Le dossier courant est : C:\Users\martienne_e Le nouveau dossier courant est : C:\Users\martienne_e\data
8.2.3. Ouverture d’un fichier : la fonction open()
Pour traiter un fichier dans un programme, la première chose à faire est d’ouvrir le fichier (un fichier est comme un livre : il faut l’ouvrir avant de pouvoir le lire !). C’est la fonction open() qui permet d’ouvrir un fichier. Elle prend en paramètres :
une chaîne (ou une variable de type chaîne) contenant le nom complet du fichier à ouvrir
une chaîne (ou une variable de type chaîne) représentant le mode d’ouverture du fichier.
Le mode d’ouverture d’un fichier va déterminer le type du fichier et la manière dont on va l’utiliser. Il est représenté par une chaîne pouvant contenir les caractères suivants :
't'pour un fichier de type texte (type par défaut).'b'pour un fichier de type binaire.'r'pour ouvrir un fichier en lecture seule, ce qui signifie qu’il sera possible de lire les données qu’il contient mais pas d’y écrire des données.'w'pour ouvrir un fichier en écriture. Dans ce mode, il sera uniquement possible d’écrire dans le fichier. Si le fichier existe déjà, tout son contenu sera remplacé par les nouvelles données écrites par le programme. Si le fichier n’existe pas, il sera créé.'a'pour ouvrir un fichier en ajout. Dans ce mode, il sera uniquement possible d’écrire dans le fichier. Si le fichier existe déjà, les données écrites viendront s’ajouter au contenu du fichier. Si le fichier n’existe pas, il sera créé.'x'pour ouvrir un fichier en écriture et en création exclusive. Dans ce mode, le fichier ne doit pas exister sinon une erreur se produit. Le programme va créer le fichier et écrire les données qu’il produit dedans.
Voici deux exemples de modes d’ouverture pouvant être fournis en paramètres de la fonction open() :
'tr': fichier texte à ouvrir en lecture seule'bw': fichier binaire à ouvrir en écriture.
Tout interpréteur Python considère par défaut que l’encodage des
fichiers texte est celui du système utilisé (exemple : cp1252 sous
Windows). Pour ouvrir un fichier texte en utilisant un encodage
différent de celui par défaut, il faut ajouter à la fonction open()
un troisième paramètre optionnel, nommé encoding, dont la valeur est
une chaîne correspondant au nom de l’encodage à utiliser.
La fonction retourne en résultat un descripteur de fichier (ou objet fichier). Ce descripteur peut être comparé à un curseur pointant sur un caractère précis du fichier, et dont la position va varier en fonction des différentes opérations qui seront effectuées sur le fichier (lectures et/ou écritures). Un descripteur est positionné :
au tout début du fichier (c’est-à-dire sur le premier caractère) lorsque le mode d’ouverture est
r,wouxà la fin du fichier (c’est-à-dire juste après le dernier caractère) lorsque le mode d’ouverture est
a.
Voici des exemples d’utilisation de la fonction open() :
fichtxt = open('data.txt', 'rt', encoding='UTF-8')
print(f"Descripteur de fichier : {fichtxt}")
Descripteur de fichier : <_io.TextIOWrapper name='data.txt' mode='rt' encoding='UTF-8'>
La fonction ouvre en lecture seule le fichier texte data.txt situé
dans le dossier courant. L’encodage utilisé est UTF-8. Elle retourne le
descripteur du fichier dans la variable fichtxt.
fichdata = open('sample.txt', 'rt')
print(f"Descripteur de fichier : {fichdata}")
Descripteur de fichier : <_io.TextIOWrapper name='sample.txt' mode='rt' encoding='cp1252'>
La fonction ouvre en lecture seule le fichier texte sample.txt situé
dans le dossier courant. L’encodage utilisé est celui par défaut :
cp1252 (Windows). Elle retourne le descripteur du fichier dans la
variable fichdata.
8.2.4. Fermeture d’un fichier : la méthode close()
Dans un programme, dès qu’un fichier n’est plus utilisé il doit être fermé (comme un livre !!). La méthode close() permet de fermer un fichier. Elle ne prend aucun paramètre et s’applique au descripteur du fichier à fermer (valeur de retour de la fonction open()).
Voici les deux exemples précédents, dans lesquels ont été ajoutées les fermetures des deux fichiers.
# Ouverture du fichier
fichtxt = open('data.txt', 'rt', encoding='UTF-8')
# Affichage de l'objet référençant le fichier
print(f"Descripteur du fichier : {fichtxt}")
# Fermeture du fichier
fichtxt.close()
Descripteur du fichier : <_io.TextIOWrapper name='data.txt' mode='rt' encoding='UTF-8'>
# Ouverture du fichier
fichdata = open('sample.txt', 'rt')
# Affichage de l'objet référençant le fichier
print(f"Descripteur du fichier : {fichdata}")
# Fermeture du fichier
fichdata.close()
Descripteur du fichier : <_io.TextIOWrapper name='sample.txt' mode='rt' encoding='cp1252'>
Un fichier ouvert dans un programme et non fermé avant la fin du programme risque d’être endommagé. Il faut donc bien penser à fermer un fichier dès qu’il n’est plus utilisé. L’instruction with, que nous aborderons plus loin dans ce chapitre, permet la fermeture implicite et donc l’utilisation sécurisée d’un fichier.
8.2.5. Lecture intégrale d’un fichier : les méthodes read() et readlines()
La méthode read() s’applique à un descripteur de fichier, et permet de lire tout son contenu à partir de la position courante du descripteur. Lorsqu’aucun paramètre ne lui est fourni, elle retourne une chaîne contenant tous les caractères contenus dans le fichier, à partir de la position du descripteur jusqu’à la fin du fichier. Dans ce cas, après l’exécution de read(), le descripteur est positionné à la fin du fichier.
Voici un exemple de lecture complète et d’affichage du contenu d’un
fichier nommé data.txt (Cliquer ici pour visualiser le contenu du
fichier data.txt).
# Ouverture du fichier
# Le descripteur fichtxt est positionné sur le premier caractère du fichier
fichtxt = open('data.txt', 'rt', encoding='UTF-8')
# Lecture de tous les caractères et stockage dans une chaîne
contenu = fichtxt.read()
# Fermeture du fichier
fichtxt.close()
# Affichage de la chaîne
print(contenu)
Souvent, pour s’amuser, les hommes d’équipage
Prennent des albatros, vastes oiseaux des mers,
Qui suivent, indolents compagnons de voyage,
Le navire glissant sur les gouffres amers.
A peine les ont-ils déposés sur les planches,
Que ces rois de l’azur, maladroits et honteux,
Laissent piteusement leurs grandes ailes blanches
Comme des avirons traîner à côté d’eux.
Ce voyageur ailé, comme il est gauche et veule !
Lui, naguère si beau, qu’il est comique et laid !
L’un agace son bec avec un brûle-gueule,
L’autre mime, en boitant, l’infirme qui volait !
Le Poète est semblable au prince des nuées
Qui hante la tempête et se rit de l’archer ;
Exilé sur le sol au milieu des huées,
Ses ailes de géant l’empêchent de marcher.
Charles Baudelaire
Il est possible de fournir en paramètre de la fonction read() un nombre entier indiquant le nombre de caractères à lire (à partir de la position du descripteur). Dans ce cas, après l’exécution de read(), le descripteur est positionné sur le premier caractère non lu du fichier.
L’exemple suivant montre comment lire uniquement les 15 premiers caractères d’un fichier.
# Ouverture du fichier
# Le descripteur fichtxt est positionné sur le premier caractère du fichier
fichtxt = open('data.txt', 'rt', encoding='UTF-8')
# Lecture des 15 premiers caractères et stockage dans une chaîne
contenu = fichtxt.read(15)
# Fermeture du fichier
fichtxt.close()
# Affichage de la chaîne
print(contenu)
Souvent, pour s
Tout comme la méthode read(), la méthode readlines() permet de lire le contenu d’un fichier. Elle s’applique au descripteur d’un fichier, et retourne le contenu du fichier (toujour à partir de la position du descripteur !) sous la forme d’une liste de chaînes, où chaque chaîne correspond à une ligne du fichier (1re chaîne = 1re ligne, 2e chaîne = 2e ligne, etc). Il s’agit donc d’une méthode adaptée pour effectuer un traitement ligne par ligne du contenu d’un fichier. Lorsqu’aucun paramètre ne lui est fourni, elle retourne toutes les lignes du fichier situées entre la position courante du descripteur et la fin du fichier (après son exécution, le descripteur est positionné à la fin du fichier). Il est possible de stopper la lecture des lignes lorsqu’un nombre de caractères a été atteint. Il suffit pour cela de fournir ce nombre en paramètre de la fonction. Dans ce cas, la lecture des lignes s’arrête lorsque le nombre de caractères souhaité a été atteint (et le descripteur est positionné sur le premier caractère non lu du fichier).
Le programme suivant lit toutes les lignes du fichier data.txt,
affiche la liste de chaînes obtenues, puis chaque ligne du fichier une
par une.
# Ouverture du fichier
# Le descripteur fichtxt est positionné sur le premier caractère du fichier
fichtxt = open('data.txt', 'rt', encoding='UTF-8')
# Lecture des lignes et stockage dans une liste de chaînes
lignes = fichtxt.readlines()
# Fermeture du fichier
fichtxt.close()
# Affichage de la liste de chaînes
print(f"Liste des chaînes lues dans le fichier : \n{lignes}\n")
# Affichage des lignes une par une
print("Affichage ligne par ligne :\n")
for l in lignes:
print(l, end="")
Liste des chaînes lues dans le fichier : ['Souvent, pour s’amuser, les hommes d’équipagen', 'Prennent des albatros, vastes oiseaux des mers,n', 'Qui suivent, indolents compagnons de voyage,n', 'Le navire glissant sur les gouffres amers.n', 'n', 'A peine les ont-ils déposés sur les planches,n', 'Que ces rois de l’azur, maladroits et honteux,n', 'Laissent piteusement leurs grandes ailes blanchesn', 'Comme des avirons traîner à côté d’eux.n', 'n', 'Ce voyageur ailé, comme il est gauche et veule !n', 'Lui, naguère si beau, qu’il est comique et laid !n', 'L’un agace son bec avec un brûle-gueule,n', 'L’autre mime, en boitant, l’infirme qui volait !n', 'n', 'Le Poète est semblable au prince des nuéesn', 'Qui hante la tempête et se rit de l’archer ;n', 'Exilé sur le sol au milieu des huées,n', 'Ses ailes de géant l’empêchent de marcher.n', 'n', 'Charles Baudelaire'] Affichage ligne par ligne : Souvent, pour s’amuser, les hommes d’équipage Prennent des albatros, vastes oiseaux des mers, Qui suivent, indolents compagnons de voyage, Le navire glissant sur les gouffres amers. A peine les ont-ils déposés sur les planches, Que ces rois de l’azur, maladroits et honteux, Laissent piteusement leurs grandes ailes blanches Comme des avirons traîner à côté d’eux. Ce voyageur ailé, comme il est gauche et veule ! Lui, naguère si beau, qu’il est comique et laid ! L’un agace son bec avec un brûle-gueule, L’autre mime, en boitant, l’infirme qui volait ! Le Poète est semblable au prince des nuées Qui hante la tempête et se rit de l’archer ; Exilé sur le sol au milieu des huées, Ses ailes de géant l’empêchent de marcher. Charles Baudelaire
Dans la liste de chaînes retournée par readlines(), on peut
remarquer que chaque chaîne se termine par le caractère spécial de
retour à la ligne \n.
Le programme suivant lit les lignes du fichier data.txt jusqu’à ce
qu’une limite de 100 caractères soit atteinte. Il affiche ensuite une
par une les lignes lues.
# Ouverture du fichier
# Le descripteur fichtxt est positionné sur le premier caractère du fichier
fichtxt = open('data.txt', 'rt', encoding='UTF-8')
# Lecture des lignes et stockage dans une liste de chaînes, jusqu'au 100e caractère
lignes = fichtxt.readlines(100)
# Fermeture du fichier
fichtxt.close()
# Affichage des lignes une par une
print("Affichage ligne par ligne :\n")
for l in lignes:
print(l, end="")
Affichage ligne par ligne :
Souvent, pour s’amuser, les hommes d’équipage
Prennent des albatros, vastes oiseaux des mers,
Qui suivent, indolents compagnons de voyage,
On remarque que seules les 3 premières lignes du fichier ont été lues, ce qui signifie que le 100e caractère doit se trouver quelque part sur la 3e ligne.
8.2.6. Écriture dans un fichier : les méthodes write() et writelines()
La méthode write() s’applique à un descripteur de fichier, prend en paramètre une chaîne, et permet d’écrire cette chaîne dans le fichier à la position courante du descripteur. Cela suppose donc que le fichier soit ouvert soit en écriture, soit en ajout, et que toutes les données à écrire dans le fichier soient converties au préalable en chaînes. Après l’exécution de write(), le descripteur est positionné immédiatement après le dernier caractère écrit. Ainsi, lorsque plusieurs appels à write() sont effectués successivement sur le même descripteur de fichier, les chaînes sont écrites les unes à la suite des autres dans le fichier.
Le programme suivant copie le contenu du fichier data.txt dans un
fichier data_copie.txt. La méthode read() est utilisée pour lire
le contenu du fichier data.txt.
# Ouverture du fichier data.txt en lecture seule
# Le descripteur original est positionné sur le premier caractère du fichier
original = open('data.txt', 'rt', encoding='UTF-8')
# Lecture du contenu du fichier data.txt
contenu = original.read()
# Fermeture du fichier data.txt
original.close()
# Ouverture du fichier data_copie.txt en écriture
# Le descripteur copie est positionné sur le premier caractère du fichier
copie = open('data_copie.txt', 'wt', encoding='UTF-8')
# Ecriture du contenu de data.txt dans data_copie.txt
copie.write(contenu)
# Fermeture du fichier data_copie.txt
copie.close()
Le programme suivant ajoute une chaîne à la fin du fichier
data_copie.txt créé précédemment, puis affiche le contenu de ce
fichier.
# Ouverture du fichier data_copie.txt en ajout
# Le descripteur fich est positionné à la fin du fichier (après le dernier caractère)
fich = open('data_copie.txt', 'at', encoding='UTF-8')
# Ecriture de la chaîne à la fin du fichier
fich.write('\nNé le 9 avril 1821 à Paris, mort le 31 août 1867 à Paris.\n')
# Ouverture du fichier data_copie.txt en lecture
# Le descripteur fich est positionné au début du fichier
fich = open('data_copie.txt', 'rt', encoding='UTF-8')
# Lecture du contenu du fichier après ajout
contenu = fich.read()
# Affichage du contenu
print(contenu)
# Fermeture du fichier
fich.close()
Souvent, pour s’amuser, les hommes d’équipage
Prennent des albatros, vastes oiseaux des mers,
Qui suivent, indolents compagnons de voyage,
Le navire glissant sur les gouffres amers.
A peine les ont-ils déposés sur les planches,
Que ces rois de l’azur, maladroits et honteux,
Laissent piteusement leurs grandes ailes blanches
Comme des avirons traîner à côté d’eux.
Ce voyageur ailé, comme il est gauche et veule !
Lui, naguère si beau, qu’il est comique et laid !
L’un agace son bec avec un brûle-gueule,
L’autre mime, en boitant, l’infirme qui volait !
Le Poète est semblable au prince des nuées
Qui hante la tempête et se rit de l’archer ;
Exilé sur le sol au milieu des huées,
Ses ailes de géant l’empêchent de marcher.
Charles Baudelaire
Né le 9 avril 1821 à Paris, mort le 31 août 1867 à Paris.
La méthode writelines() s’applique à un descripteur de fichier,
prend en paramètre une liste de chaînes, et permet d’écrire toutes les
chaînes de la liste dans le fichier, les unes après les autres, à partir
de la position courante du descripteur. Après son exécution, le
descripteur est positionné immédiatement après le dernier caractère
écrit. Le programme suivant ajoute deux chaînes à la fin du fichier
data_copie.txt créé précédemment, puis affiche le contenu de ce
fichier.
# Liste contenant les deux chaînes à ajouter
chajout = ['Père : Joseph-François Baudelaire\n', 'Mère : Caroline Aupick\n']
# Ouverture du fichier data_copie.txt en ajout
# Le descripteur fich est positionné à la fin du fichier (après le dernier caractère)
fich = open('data_copie.txt', 'at', encoding='UTF-8')
# Ecriture des chaînes de la liste à la fin du fichier
fich.writelines(chajout)
# Ouverture du fichier data_copie.txt en lecture
# Le descripteur fich est positionné au début du fichier
fich = open('data_copie.txt', 'rt', encoding='UTF-8')
# Lecture du contenu du fichier après ajout
contenu = fich.read()
# Affichage du contenu
print(contenu)
# Fermeture du fichier
fich.close()
Souvent, pour s’amuser, les hommes d’équipage
Prennent des albatros, vastes oiseaux des mers,
Qui suivent, indolents compagnons de voyage,
Le navire glissant sur les gouffres amers.
A peine les ont-ils déposés sur les planches,
Que ces rois de l’azur, maladroits et honteux,
Laissent piteusement leurs grandes ailes blanches
Comme des avirons traîner à côté d’eux.
Ce voyageur ailé, comme il est gauche et veule !
Lui, naguère si beau, qu’il est comique et laid !
L’un agace son bec avec un brûle-gueule,
L’autre mime, en boitant, l’infirme qui volait !
Le Poète est semblable au prince des nuées
Qui hante la tempête et se rit de l’archer ;
Exilé sur le sol au milieu des huées,
Ses ailes de géant l’empêchent de marcher.
Charles Baudelaire
Né le 9 avril 1821 à Paris, mort le 31 août 1867 à Paris.
Père : Joseph-François Baudelaire
Mère : Caroline Aupick
8.2.7. L’instruction with et la fermeture automatique de fichier
Nous avons évoqué précédemment l’importance de fermer les fichiers, dès que leurs utilisations sont terminées. Pour ne pas avoir à se soucier de la fermeture des fichiers (et accessoirement ne pas risquer de perdre les données qu’ils contiennent !), il est possible (voire même fortement recommandé !) d’utiliser l’instruction with. Sa syntaxe est la suivante :
with open() as desc_fich:
bloc
où :
open()est un appel à la fonction du même nom permettant d’ouvrir un fichierdesc_fichest un descripteur de fichier, dont la valeur est celle retournée par l’appel àopen()blocest un bloc d’instructions, contenant notamment des opérations sur le fichier de descripteurdesc_fich.
L’intérêt de cette instruction with est qu’elle va fermer
automatiquement le fichier de descripteur desc_fich, dès que
l’exécution du bloc d’instructions sera terminée, et même si cette
terminaison est dûe à une erreur. Utiliser with, c’est donc avoir
l’assurance que le fichier sera fermé quoi qu’il arrive.
Le programme suivant lit le contenu intégral d’un fichier demo.txt
puis l’affiche, en utilisant l’instruction with (Cliquer ici pour
visualiser le contenu du fichier demo.txt).
# Ouverture du fichier demo.txt en lecture
# Le descripteur fich est positionné au début du fichier
with open('demo.txt', 'rt', encoding='UTF-8') as fich:
contenu = fich.read()
print(contenu)
Ligne 1
Ligne 2
Ligne 3
Ligne 4
Ligne 5
Ligne 6
Ligne 7
Ligne 8
Ligne 9
Ligne 10
Il est possible d’imbriquer deux instructions with (ou plus !),
notamment dans un programme manipulant plusieurs fichiers texte. Le
programme suivant copie le contenu du fichier demo.txt dans le
fichier demo_copie.txt. Deux instructions with sont utilisées :
une première pour ouvrir le fichier
demo.txten lecture seuleune seconde, imbriquée dans la première, pour l’ouverture du fichier
demo_copie.txten écriture.
# Ouverture du fichier demo.txt en lecture
# Le descripteur fich est positionné au début du fichier
with open('demo.txt', 'rt', encoding='UTF-8') as fich:
# Ouverture du fichier demo_copie.txt en écriture
# Le descripteur nouveau est positionné au début du fichier
with open('demo_copie.txt', 'wt', encoding='UTF-8') as nouveau:
contenu = fich.read() # Lecture du contenu de demo.txt
nouveau.write(contenu) # Ecriture du même contenu dans demo_copie.txt
Notons au passage que l’imbrication des instructions with aurait pu se faire « dans l’autre sens ».
with open('demo_copie.txt', 'wt', encoding='UTF-8') as nouveau:
with open('demo.txt', 'rt', encoding='UTF-8') as fich:
contenu = fich.read()
nouveau.write(contenu)
8.2.8. Parcours d’un fichier ligne par ligne : la boucle for et la méthode readline() associée à une boucle while
La boucle for permet d’effectuer un traitement ligne par ligne d’un
fichier texte. Sa syntaxe est la suivante :
for ligne in desc_fich:
bloc
où :
ligneest une variable de type chaînedesc_fichest le descripteur du fichier à parcourirblocest un bloc d’instructions.
La variable ligne va prendre pour valeurs successives, une par une,
toutes les lignes du fichier (une ligne = une chaîne) à partir de la
position courante du descripteur. Chaque ligne sera terminée par le
caractère de retour à la ligne '\n'. Pour chaque ligne du fichier,
une exécution de bloc est réalisée.
Le programme suivant effectue un parcours ligne par ligne du fichier
data_copie.txt. Sur chaque ligne, l’application de la méthode
strip() permet de supprimer le caractère de retour à la ligne
'\n'. Puis, le nombre de caractères de la ligne est affiché à
l’écran.
# Ouverture du fichier data_copie.txt en lecture
# Le descripteur fich est positionné au début du fichier
with open('data_copie.txt', 'rt', encoding='UTF-8') as fich:
# Parcours du fichier ligne par ligne, suppression du caractère de retour à la ligne \n et affichage du nombre de caractères de chaque ligne
for ligne in fich:
ligne = ligne.strip('\n')
print(len(ligne))
45
47
44
42
0
45
46
49
39
0
48
49
40
48
0
42
44
37
42
0
18
57
33
22
On remarque que certaines lignes comportent 0 caractère. Ce sont les
lignes vides qui ne contiennent que le caractère de retour à la ligne
'\n' (caractère que la méthode strip() permet de supprimer avant
le calcul du nombre de caractères).
La méthode readline() permet de lire une ligne dans un fichier (toujours à partir de la position courante du descripteur du fichier !!), et de positionner le descripteur sur le premier caractère de la ligne suivante. Elle retourne :
le contenu de la ligne lue (sous la forme d’une chaîne terminée par
'\n'), si la fin du fichier n’est pas encore atteinteune chaîne vide si la fin de fichier est atteinte.
Le programme suivant lit puis affiche la première ligne du fichier nommé
demo.txt (après lui avoir retiré le caractère de fin de ligne).
# Ouverture du fichier demo.txt en lecture
# Le descripteur fich est positionné au début du fichier
with open('demo.txt', 'rt', encoding='UTF-8') as fich:
premligne = fich.readline() # Lecture de la première ligne
premligne = premligne.strip('\n') # Suppression du caractère de fin de ligne
print(f"Voici le contenu de la première ligne du fichier : {premligne}.")
Voici le contenu de la première ligne du fichier : Ligne 1.
Associée à une boucle while, la méthode readline() permet
d’effectuer un parcours ligne par ligne d’un fichier, pour appliquer à
chaque ligne le même traitement. Le programme ci-dessous parcourt toutes
les lignes du fichier demo.txt en affichant pour chacune son contenu
et son nombre de caractères.
# Ouverture du fichier demo.txt en lecture
# Le descripteur fich est positionné au début du fichier
with open('demo.txt', 'rt', encoding='UTF-8') as fich:
premligne = fich.readline() # Lecture de la première ligne
while premligne: # Equivalent à while premligne != '':
premligne = premligne.strip('\n') # Suppression du caractère de fin de ligne
print(f"Contenu : {premligne}, Nombre de caractères : {len(premligne)}")
premligne = fich.readline() # Lecture de la ligne suivante
Contenu : Ligne 1, Nombre de caractères : 7
Contenu : Ligne 2, Nombre de caractères : 7
Contenu : Ligne 3, Nombre de caractères : 7
Contenu : Ligne 4, Nombre de caractères : 7
Contenu : Ligne 5, Nombre de caractères : 7
Contenu : Ligne 6, Nombre de caractères : 7
Contenu : Ligne 7, Nombre de caractères : 7
Contenu : Ligne 8, Nombre de caractères : 7
Contenu : Ligne 9, Nombre de caractères : 7
Contenu : Ligne 10, Nombre de caractères : 8
8.2.9. Positionnement d’un descripteur de fichier : la méthode seek()
Nous avons vu précédemment que les opérations de lecture et d’écriture dans un fichier s’effectuent toujours à partir de la position courante du descripteur dans le fichier. Un descripteur de fichier se crée à l’aide de la fonction open(), qui le positionne soit au début du fichier (premier caractère) soit à la fin (après le dernier caractère) selon le mode d’ouverture choisi. Les différentes opérations de lecture et/ou d’écriture modifient ensuite la position du descripteur dans le fichier. La méthode seek() s’applique à un descripteur de fichier et prend en paramètre un nombre correspondant à la position d’un caractère (0 pour le premier, 1 pour le deuxième, 2 pour le troisième, etc). Elle ne retourne aucun résultat mais positionne le descripteur sur le caractère situé à la position fournie en paramètre.
Le programme suivant lit puis affiche plusieurs fois le contenu du
fichier data.txt : dans sa totalité, à partir du caractère de la
position 15 puis à partir du caractère de la position 50.
# Ouverture du fichier data.txt
# Le descripteur fichtxt est positionné sur le premier caractère du fichier
with open('data.txt', 'rt', encoding='UTF-8') as fichtxt:
complet = fichtxt.read() # Lecture de la totalité du fichier
print(f"Contenu complet du fichier :\n\n{complet}\n") # Affichage de la totalité du fichier
fichtxt.seek(15) # Positionnement de fichtxt sur le caractère situé à la position 15
partiel = fichtxt.read() # Lecture du fichier (à partir de la position de fichtxt : position 15)
print(f"Contenu partiel du fichier à partir de la position 15 :\n\n{partiel}\n") # Affichage
fichtxt.seek(50) # Positionnement de fichtxt sur le caractère situé à la position 50
partiel = fichtxt.read() # Lecture du fichier (à partir de la position de fichtxt : position 50)
print(f"Contenu partiel du fichier à partir de la position 50 :\n\n{partiel}") # Affichage
Contenu complet du fichier :
Souvent, pour s’amuser, les hommes d’équipage
Prennent des albatros, vastes oiseaux des mers,
Qui suivent, indolents compagnons de voyage,
Le navire glissant sur les gouffres amers.
A peine les ont-ils déposés sur les planches,
Que ces rois de l’azur, maladroits et honteux,
Laissent piteusement leurs grandes ailes blanches
Comme des avirons traîner à côté d’eux.
Ce voyageur ailé, comme il est gauche et veule !
Lui, naguère si beau, qu’il est comique et laid !
L’un agace son bec avec un brûle-gueule,
L’autre mime, en boitant, l’infirme qui volait !
Le Poète est semblable au prince des nuées
Qui hante la tempête et se rit de l’archer ;
Exilé sur le sol au milieu des huées,
Ses ailes de géant l’empêchent de marcher.
Charles Baudelaire
Contenu partiel du fichier à partir de la position 15 :
’amuser, les hommes d’équipage
Prennent des albatros, vastes oiseaux des mers,
Qui suivent, indolents compagnons de voyage,
Le navire glissant sur les gouffres amers.
A peine les ont-ils déposés sur les planches,
Que ces rois de l’azur, maladroits et honteux,
Laissent piteusement leurs grandes ailes blanches
Comme des avirons traîner à côté d’eux.
Ce voyageur ailé, comme il est gauche et veule !
Lui, naguère si beau, qu’il est comique et laid !
L’un agace son bec avec un brûle-gueule,
L’autre mime, en boitant, l’infirme qui volait !
Le Poète est semblable au prince des nuées
Qui hante la tempête et se rit de l’archer ;
Exilé sur le sol au milieu des huées,
Ses ailes de géant l’empêchent de marcher.
Charles Baudelaire
Contenu partiel du fichier à partir de la position 50 :
Prennent des albatros, vastes oiseaux des mers,
Qui suivent, indolents compagnons de voyage,
Le navire glissant sur les gouffres amers.
A peine les ont-ils déposés sur les planches,
Que ces rois de l’azur, maladroits et honteux,
Laissent piteusement leurs grandes ailes blanches
Comme des avirons traîner à côté d’eux.
Ce voyageur ailé, comme il est gauche et veule !
Lui, naguère si beau, qu’il est comique et laid !
L’un agace son bec avec un brûle-gueule,
L’autre mime, en boitant, l’infirme qui volait !
Le Poète est semblable au prince des nuées
Qui hante la tempête et se rit de l’archer ;
Exilé sur le sol au milieu des huées,
Ses ailes de géant l’empêchent de marcher.
Charles Baudelaire
8.3. Utilisation des fichiers au format CSV en Python : le module csv
Dans cette section, nous présentons les principales fonctions du module CSV de Python, permettant le traitement des fichiers texte au format CSV.
8.3.1. Qu’est-ce que le format CSV ?
CSV signifie Comma-Separated Values, autrement dit valeurs séparées par des virgules. Il s’agit d’un format de données textuelles permettant de stocker des données tabulaires, c’est-à-dire des données qui pourraient être représentées dans un tableau. Il est très utilisé dans les systèmes de gestion de bases de données, ainsi que dans les logiciels tableurs, pour faciliter l’échange de données d’un logiciel à l’autre.
Dans un fichier au format CSV :
chaque ligne correspond à une ligne d’un tableau, la première ligne pouvant contenir les intitulés des différents colonnes (cette première ligne d’intitulés n’est pas obligatoire)
sur chaque ligne, les contenus des différentes colonnes sont séparés à l’aide d’un caractère séparateur
certaines colonnes peuvent avoir un contenu vide.
Voici ci-dessous un exemple de fichier au format CSV. La première ligne est la ligne d’intitulés (7 intitulés, donc 7 colonnes). Le caractère séparateur est la virgule « , ». Aucune des lignes ne comporte de colonne vide.

Fichier au format CSV
8.3.2. Dialecte d’un fichier CSV
Le dialecte d’un fichier CSV désigne l’ensemble des règles utilisées pour formater les données qu’il contient. Le format CSV n’étant pas normalisé, il existe de nombreux dialectes différents. Dans l’exemple ci-dessous, le dialecte du fichier se compose entre autres des trois règles de formatage suivantes :
l’utilisation du point-virgule « ; » comme caractère séparateur des colonnes
les guillemets doubles anglo-saxons « “” » autour des données textuelles (pour les distinguer des données numériques)
l’utilisation du point « . » comme séparateur décimal des données numériques.

Les fonctions has_header() et sniff() fournies par le module CSV
prennent en paramètre un extrait du contenu d’un fichier au format CSV,
puis analysent cet extrait. La fonction has_reader() retourne un
booléen dont la valeur est True si la première ligne du fichier est
bien une ligne d’intitulés, et False sinon. La fonction sniff()
retourne un objet dialecte contenant toutes les règles de formatage
du fichier, résumées dans des variables telles que :
lineterminator: le caractère de fin de lignedelimiter: le caractère séparateurquotechar: le caractère utilisé pour entourer les données susceptibles de contenir le caractère séparateuretc
Le programme ci-dessous utilise ces deux fonctions pour analyser un
fichier nommé donnees.csv puis afficher le résultat de son analyse
(Cliquer ici pour visualiser le contenu du fichier
donnees.csv). Notons que le fichier à analyser
doit être préalablement ouvert en lecture.
import os, csv
with open('donnees.csv', 'rt', encoding='UTF-8') as f:
extrait = f.read()
intitules = csv.Sniffer().has_header(extrait) # Existence ou non d'une ligne d'intitulés
dialect = csv.Sniffer().sniff(extrait) # Analyse du dialecte utilisé pour le formatage
if intitules:
print("Le fichier analysé possède une ligne d'intitulés.")
else:
print("Le fichier analysé ne possède pas de ligne d'intitulés.")
print("Voici quelques propriétés du dialecte utilisé :")
print(f"Caractère séparateur : {dialect.delimiter}")
print(f"Caractère entourant les données pouvant contenir le caractère séparateur : {dialect.quotechar}")
Le fichier analysé possède une ligne d'intitulés.
Voici quelques propriétés du dialecte utilisé :
Caractère séparateur : ;
Caractère entourant les données pouvant contenir le caractère séparateur : "
Les résultats du programme sont bien conformes aux caractéristiques du
fichier donnees.csv dont voici ci-dessous un extrait.

Extrait du fichier donnees.csv
La première ligne est bien une ligne d’intitulés. Le caractère
séparateur est bien le point-virgule « ; ». De plus, les données
textuelles susceptibles de contenir le caractère séparateur sont
entourés du caractère « ” » (caractère nommé quotechar).
8.3.3. Lecture d’un fichier CSV
Pour lire les données textuelles contenues dans un fichier CSV, il faut
tout d’abord créer un lecteur (un reader) de ce fichier,
c’est-à-dire un objet capable de décoder le fichier. La lecture des
données s’effectue ensuite à partir de ce lecteur.
8.3.3.1. Création d’un lecteur : la fonction csv.reader()
La fonction csv.reader() prend en paramètres :
le descripteur du fichier CSV à lire, qui doit être ouvert en lecture
un objet dialecte contenant le dialecte du fichier CSV
et retourne le lecteur associé au fichier CSV. Le dialecte du fichier CSV à lire peut être obtenu en utilisant la méthode sniff() vue précédemment.
Le programme suivant ouvre le fichier donnees.csv, récupère son
dialecte, re-positionne le descripteur au début du fichier
(l’instruction f.read() a eu pour effet de le déplacer en fin de
fichier) puis crée un lecteur pour le fichier. Notons que la variable
dialect contenant le dialecte (valeur de retour de la méthode
sniff()) est passée en paramètre de la fonction csv.reader().
import os, csv
# Ouverture du fichier donnees.csv
# Le descripteur f est positionné sur le premier caractère du fichier
with open('donnees.csv', 'rt', encoding='UTF-8') as f:
dialect = csv.Sniffer().sniff(f.read()) # Récupération du dialecte. Après f.read(), le descripteur f est positionné à la fin du fichier
f.seek(0) # Re-positionnement de f au début du fichier (indispensable avant la création du lecteur)
lecteur = csv.reader(f, dialect) # Création du lecteur
8.3.3.2. Lecture des données à partir du lecteur
Un lecteur de fichier (résultat de la fonction csv.reader()) est un
objet itérable. Il peut donc être utilisé pour parcourir ligne par ligne
les données se trouvant dans le fichier. Ce parcours s’effectue à l’aide
d’une boucle for dont la syntaxe est la suivante :
for ligne in lect:
bloc
où :
ligneest une variablelectest lecteurblocest un bloc d’instructions.
La variable ligne va prendre successivement pour valeurs toutes les
lignes du fichier, de la première à la dernière. Pour chaque ligne, une
exécution de bloc est effectuée. Chaque ligne placée dans la
variable ligne est une liste de chaînes, où la première chaîne
correspond à la première valeur de la ligne, la deuxième chaîne à la
deuxième valeur, etc. On accède à chaque valeur de la ligne à l’aide de
sa position dans la liste.
A la fin d’une itération sur un lecteur, le descripteur du fichier se situe à la fin du fichier. Pour pouvoir refaire une itération sur le lecteur, il faut re-positionner le descripteur au début du fichier avec la méthode seek().
Le programme suivant effectue deux parcours du contenu du fichier
donnees.csv ligne par ligne, à l’aide de son lecteur et d’une boucle
for. Lors du premier parcours, chaque ligne est affichée en séparant
les différentes valeurs de la ligne par un tiret horizontal. Lors du
second parcours, chaque ligne est affichée en séparant les différentes
valeurs de la ligne par un trait vertical.
import os, csv
# Ouverture du fichier donnees.csv
# Le descripteur f est positionné sur le premier caractère du fichier
with open('donnees.csv', 'rt', encoding='UTF-8') as f:
dialect = csv.Sniffer().sniff(f.read()) # Récupération du dialecte. Après f.read(), le descripteur f est positionné à la fin du fichier
f.seek(0) # Re-positionnement de f au début du fichier (indispensable avant la création du lecteur)
lecteur = csv.reader(f, dialect) # Création du lecteur
print("Premier parcours : ")
for ligne in lecteur: # Premier parcours ligne par ligne du fichier à l'aide du lecteur
print(f"{ligne[0]} - {ligne[1]} - {ligne[2]} - {ligne[3]} - {ligne[4]} - {ligne[5]} - {ligne[6]}")
f.seek(0) # Re-positionnement de f au début du fichier (indispensable avant le second parcours)
print("\nSecond parcours : ")
for ligne in lecteur:
print(f"{ligne[0]} | {ligne[1]} | {ligne[2]} | {ligne[3]} | {ligne[4]} | {ligne[5]} | {ligne[6]}")
Premier parcours :
Numéro - Nom - Nbinscrits - Nbvotants - Nbblancs - Nbnuls - Nbexp
44 - Grand Est - 3864055 - 2847382 - 158769 - 54418 - 2634195
75 - Nouvelle-Aquitaine - 4462866 - 3383501 - 250345 - 103875 - 3029281
84 - Auvergne-Rhône-Alpes - 5558964 - 4136309 - 277883 - 91317 - 3767109
27 - Bourgogne-Franche-Comté - 1992557 - 1491021 - 102236 - 38647 - 1350138
53 - Bretagne - 2562764 - 1996495 - 142782 - 48102 - 1805611
24 - Centre-Val de Loire - 1837674 - 1373416 - 89671 - 33483 - 1250262
11 - Île-de-France - 7353133 - 5192986 - 320171 - 86980 - 4785835
76 - Occitanie - 4324603 - 3251774 - 238975 - 99581 - 2913218
32 - Hauts-de-France - 4256336 - 3119882 - 160771 - 68989 - 2890122
28 - Normandie - 2414345 - 1830658 - 116648 - 36854 - 1677156
52 - Pays de la Loire - 2833848 - 2164728 - 144187 - 46252 - 1974289
93 - Provence-Alpes-Côte d'Azur - 3664768 - 2656700 - 155435 - 49262 - 2452003
94 - Corse - 243000 - 147902 - 9534 - 4552 - 133816
01 - Guadeloupe - 315941 - 149057 - 8511 - 8211 - 132335
02 - Martinique - 304670 - 138469 - 11198 - 7353 - 119918
03 - Guyane - 103058 - 40088 - 3049 - 1768 - 35271
04 - La Réunion - 676080 - 401492 - 20584 - 16644 - 364264
06 - Mayotte - 92421 - 42044 - 1645 - 1997 - 38402
Second parcours :
Numéro | Nom | Nbinscrits | Nbvotants | Nbblancs | Nbnuls | Nbexp
44 | Grand Est | 3864055 | 2847382 | 158769 | 54418 | 2634195
75 | Nouvelle-Aquitaine | 4462866 | 3383501 | 250345 | 103875 | 3029281
84 | Auvergne-Rhône-Alpes | 5558964 | 4136309 | 277883 | 91317 | 3767109
27 | Bourgogne-Franche-Comté | 1992557 | 1491021 | 102236 | 38647 | 1350138
53 | Bretagne | 2562764 | 1996495 | 142782 | 48102 | 1805611
24 | Centre-Val de Loire | 1837674 | 1373416 | 89671 | 33483 | 1250262
11 | Île-de-France | 7353133 | 5192986 | 320171 | 86980 | 4785835
76 | Occitanie | 4324603 | 3251774 | 238975 | 99581 | 2913218
32 | Hauts-de-France | 4256336 | 3119882 | 160771 | 68989 | 2890122
28 | Normandie | 2414345 | 1830658 | 116648 | 36854 | 1677156
52 | Pays de la Loire | 2833848 | 2164728 | 144187 | 46252 | 1974289
93 | Provence-Alpes-Côte d'Azur | 3664768 | 2656700 | 155435 | 49262 | 2452003
94 | Corse | 243000 | 147902 | 9534 | 4552 | 133816
01 | Guadeloupe | 315941 | 149057 | 8511 | 8211 | 132335
02 | Martinique | 304670 | 138469 | 11198 | 7353 | 119918
03 | Guyane | 103058 | 40088 | 3049 | 1768 | 35271
04 | La Réunion | 676080 | 401492 | 20584 | 16644 | 364264
06 | Mayotte | 92421 | 42044 | 1645 | 1997 | 38402
La lecture du contenu d’un fichier à partir de son lecteur peut
également se faire en transformant le lecteur en une liste de listes, à
l’aide de la fonction list. La structure de la liste de listes
obtenue est la suivante :
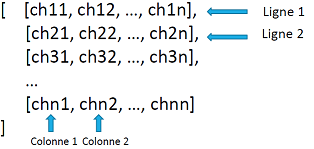
Structure de la liste de listes du lecteur
Chaque liste de la liste est une liste de chaînes, où la première chaîne est la première valeur de la liste (colonne 1), la deuxième chaîne est la deuxième valeur (colonne 2), etc. L’intérêt de cette méthode est qu’elle permet de mémoriser tout le contenu du fichier dans une liste. Le fichier peut donc être fermé une fois ses données lues, comme le montre le programme ci-dessous.
import os, csv
# Ouverture du fichier donnees.csv
# Le descripteur f est positionné sur le premier caractère du fichier
with open('donnees.csv', 'rt', encoding='UTF-8') as f:
dialect = csv.Sniffer().sniff(f.read()) # Récupération du dialecte. Après f.read(), le descripteur f est positionné à la fin du fichier
f.seek(0) # Re-positionnement de f au début du fichier (indispensable avant la création du lecteur)
lecteur = csv.reader(f, dialect) # Création du lecteur
contenu = list(lecteur) # Transformation du lecteur en une liste de listes mémorisée dans une variable
print(f"Le contenu du fichier est : \n{contenu}") # Affichage du contenu du fichier (après la fermeture du fichier)
Le contenu du fichier est :
[['Numéro', 'Nom', 'Nbinscrits', 'Nbvotants', 'Nbblancs', 'Nbnuls', 'Nbexp'], ['44', 'Grand Est', '3864055', '2847382', '158769', '54418', '2634195'], ['75', 'Nouvelle-Aquitaine', '4462866', '3383501', '250345', '103875', '3029281'], ['84', 'Auvergne-Rhône-Alpes', '5558964', '4136309', '277883', '91317', '3767109'], ['27', 'Bourgogne-Franche-Comté', '1992557', '1491021', '102236', '38647', '1350138'], ['53', 'Bretagne', '2562764', '1996495', '142782', '48102', '1805611'], ['24', 'Centre-Val de Loire', '1837674', '1373416', '89671', '33483', '1250262'], ['11', 'Île-de-France', '7353133', '5192986', '320171', '86980', '4785835'], ['76', 'Occitanie', '4324603', '3251774', '238975', '99581', '2913218'], ['32', 'Hauts-de-France', '4256336', '3119882', '160771', '68989', '2890122'], ['28', 'Normandie', '2414345', '1830658', '116648', '36854', '1677156'], ['52', 'Pays de la Loire', '2833848', '2164728', '144187', '46252', '1974289'], ['93', "Provence-Alpes-Côte d'Azur", '3664768', '2656700', '155435', '49262', '2452003'], ['94', 'Corse', '243000', '147902', '9534', '4552', '133816'], ['01', 'Guadeloupe', '315941', '149057', '8511', '8211', '132335'], ['02', 'Martinique', '304670', '138469', '11198', '7353', '119918'], ['03', 'Guyane', '103058', '40088', '3049', '1768', '35271'], ['04', 'La Réunion', '676080', '401492', '20584', '16644', '364264'], ['06', 'Mayotte', '92421', '42044', '1645', '1997', '38402']]
8.3.4. Écriture dans un fichier CSV
Pour écrire des données textuelles dans un fichier CSV, il faut tout
d’abord créer un écrivain (un writer) de ce fichier,
c’est-à-dire un objet capable d’écrire dans le fichier. L’écriture des
données s’effectue ensuite à partir de cet écrivain.
8.3.4.1. Création d’un écrivain : la fonction csv.writer()
La fonction csv.writer() prend en paramètres :
le descripteur du fichier CSV dans lequel les données doivent être écrites, qui doit être ouvert en écriture
des paramètres facultatifs précisant certains éléments du dialecte (comme par exemple la valeur du caractère séparateur (
delimiter) ou celle du caractère de fin de ligne (lineseparator)
et retourne l’écrivain associé au fichier CSV.
Le programme suivant ouvre le fichier resultats.csv en écriture,
puis crée un écrivain pour ce fichier. Le caractère séparateur est le
point-virgule et le caractère de fin de ligne '\n'.
import os, csv
with open('resultats.csv', 'wt', encoding='UTF-8') as f:
ecrivain = csv.writer(f, delimiter=";", lineterminator = "\n")
8.3.4.2. Écriture des données à l’aide de l’écrivain : la méthode writerow()
La méthode writerow() s’applique à un écrivain et permet d’écrire
une nouvelle ligne dans le fichier associé, à la position courante du
descripteur. Elle prend comme unique paramètre un tuple ou une liste de
chaînes dont les éléments sont les différentes valeurs de la ligne. Le
tuple ou la liste peut être défini(e) à l’aide de la compréhension de
liste (de tuple). Le programme suivant écrit deux lignes à la fin du
fichier resultats.csv.
import os, csv
# Ouverture du fichier resultats.csv en écriture
# Le descripteur f est positionné à la fin du fichier
with open('resultats.csv', 'wt', encoding='UTF-8') as f:
ecrivain = csv.writer(f, delimiter=";", lineterminator = "\n")
ecrivain.writerow(['Nom', 'Prénom', 'Age'])
ecrivain.writerow(('Dutilleul', 'Armand', '28'))
Voici ci-dessous le contenu du fichier resultats.csv après exécution
du programme.
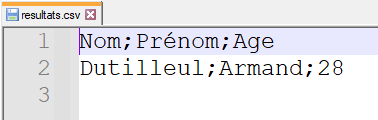
Contenu du fichier resultats.csv
8.3.5. Exemple complet
Dans cette section, nous présentons un exemple de programme traitant des
données mémorisées dans un fichier au format CSV. Le fichier de départ,
nommé notes.csv, contient sur chaque ligne le nom, le prénom d’un(e)
étudiant(e) ainsi que trois notes obtenues à des examens (Cliquer ici
pour visualiser le contenu du fichier
notes.csv).

Contenu du fichier notes.csv
Le programme parcourt ligne par ligne le fichier notes.csv afin de
calculer la moyenne des trois notes de chaque étudiant(e). Il crée un
nouveau fichier au format CSV, nommé moyennes.csv, dont le contenu
est identique à celui de notes.csv à ceci près que les trois notes
d’examens sont remplacées par les moyennes des trois notes.
import os, csv
with open('notes.csv', 'rt', encoding='UTF-8') as fnotes: # Ouverture du fichier notes.csv en lecture seule
dialect = csv.Sniffer().sniff(fnotes.read()) # Récupération du dialecte
fnotes.seek(0) # Re-positionnement du descripteur au début du fichier
lecteur = csv.reader(fnotes, dialect) # Création du lecteur du fichier notes.csv
with open('moyennes.csv', 'wt', encoding='UTF-8') as fmoy: # Ouverture du fichier moyennes.csv en écriture
ecrivain = csv.writer(fmoy, delimiter=";",lineterminator = "\n") # Création d'un écrivain du fichier moyennes.csv
for etudiant in lecteur: # Parcours ligne par ligne du fichier notes.csv à l'aide de son lecteur
nom = etudiant[0] # Stockage dans des variables des informations sur l'étudiant(e)
prenom = etudiant[1]
note1 = float(etudiant[2]) # Les 3 notes lues sont des chaînes et doivent être converties en float
note2 = float(etudiant[3])
note3 = float(etudiant[4])
moyenne = (note1+note2+note3)/3 # Calcul de la moyenne de l'étudiant(e)
ecrivain.writerow([nom, prenom, str(moyenne)]) # Ecriture des informations sur l'étudiant(e) dans le fichier moyennes.csv à l'aide de l'écrivain
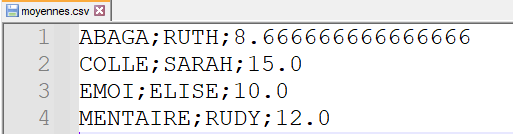
Le contenu du fichier moyennes.csv obtenu est le suivant :
Contenu du fichier moyennes.csv