
Les listes et les tuples
Contenu de la page
6. Les listes et les tuples
Dans ce chapitre, nous abordons deux types de structures de données utilisées en Python : les listes et les tuples.
6.1. Pourquoi utiliser des structures de données ?
Dans les chapitres précédents, nous n’avons utilisé que des variables simples pour stocker les informations traitées dans nos programmes (ce que nous appelons ici « variable simple » est une variable contenant un objet simple comme un entier, un réel, une chaîne ou un booléen - cf. chapitre sur les bases du langage Python). Ces informations étant peu volumineuses et peu structurées, cette technique était suffisante. Cependant, programmer en utilisant uniquement des variables simples est très largement insuffisant, voire même impossible.
Prenons l’exemple d’un programme qui doit calculer la moyenne d’une promo de 500 étudiants à un examen d’économie. Est-ce gérable de déclarer 500 variables : une variable par note ? Pas vraiment.
Autre exemple : celui d’un programme qui traite des données textuelles en appliquant un traitement identique à tous les mots d’un texte. Est-ce envisageable de compter au préalable le nombre de mots du texte pour savoir de combien de variables on a besoin ? Absolument pas. Et en supposant que cela soit possible, cela signifie qu’il faudra modifier le programme si le texte à traiter change…
Utiliser uniquement des variables simples suppose de connaître à l’avance la quantité de données à traiter, ce qui est rarement le cas sauf pour des programmes très simples. Et même dans l’hypothèse où il serait possible de quantifier précisément les données, il est inconcevable d’écrire des programmes qui gèrent des centaines, voire des milliers de variables.
Autre limitation des variables simples : elles ne permettent pas de mémoriser des données structurées. Prenons l’exemple d’un programme permettant de gérer les clients d’une entreprise commerciale. Un client est décrit à l’aide de différentes caractéristiques : numéro, nom, prénom, adresse, etc. Une variable simple ne permet pas de mémoriser toutes ces informations de types différents (chaînes, nombres, etc).
Enfin, et nous terminerons sur cette dernière limitation : les variables simples ne permettent pas de mémoriser des associations entre des informations. Pourtant, ces associations sont monnaie courante : un mot du dictionnaire et sa définition, un n° de département et le nom du département correspondant, un n° d’étudiant et l’étudiant qui lui est associé, etc. Elles ne permettent pas non plus de stocker des données multi-dimensionnelles comme des vecteurs ou des matrices de nombres.
Les structures de données ont été introduites en programmation pour pallier aux limitations des objets et variables simples. Il existe différents types de structures de données selon le langage. En python, il en existe quatre principaux :
les listes
les tuples
les dictionnaires
les ensembles.
Les listes et les tuples sont abordés dans ce chapitre. Les dictionnaires feront l’objet d’un autre chapitre.
6.2. Les listes
Une liste est une séquence d’éléments (i.e., une collection ordonnée d’objets) dont les types peuvent être différents. Chaque élément figure à une place précise dans la liste (on parle aussi d’indice, de position ou de rang) qui permet de le repérer et d’y accéder. On dit en particulier qu’une liste est indexée sur les indices de ses éléments. Le nombre d’éléments stockés dans une liste est quelconque et peut varier au cours d’un programme. Une liste est un objet Python « muable ». Cela signifie qu’on peut effectuer sur une liste des manipulations entraînant la modification de ses éléments. Une variable référençant une liste peut donc être modifiée sans passer par une affectation.
6.3. Notation et création d’une liste
La notation d’une liste s’effectue à l’aide des crochets :
[pour indiquer le début de la liste]pour indiquer la fin de la liste
À l’intérieur des crochets, les différents éléments de la liste sont
séparés par des virgules. Par exemple :
[3.1416, 25, 154, "fromage", "dessert"]. Il existe un cas
particulier de liste : la liste vide ne contenant aucun élément. Dans ce
cas, la notation s’effectue avec uniquement les crochets : []. Les
éléments d’une liste sont indexés sur leur rang dans la liste, en
commençant par 0 (rang du premier élément), puis 1 (rang du deuxième
élément), etc.
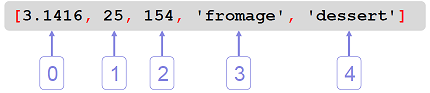
Exemple de liste
Une liste doit être mémorisée dans une variable (on parle alors de
variable structurée). Par exemple :
bazar = [3.1416, 25, 154, "fromage", "dessert"]. Le nom de la
variable est alors appelé son identifiant et permet de la référencer
dans le programme. Après l’affectation de l’exemple précédent, la
variable bazar référence la liste
[3.1416, 25, 154, "fromage", "dessert"].
6.4. Accès aux éléments d’une liste
L’accès aux éléments d’une liste se fait à l’aide de leurs rangs dans la liste avec la notation suivante :
id_liste[pos]
où id_liste est le nom de la variable référençant la liste et
pos est la position occupée par l’élément dans la liste. La position
indiquée doit correspondre à un élément, sous peine de déclencher une
erreur d’exécution. Le programme suivant effectue des accès aux éléments
d’une liste.
bazar = [3.1416, 25, 154, "fromage", "dessert"]
print(f"Le premier élément de la liste est : {bazar[0]}")
print(f"Le troisième élément de la liste est : {bazar[2]}")
print(f"Le dernier élément de la liste est : {bazar[4]}")
print(f"Le sixième élément de la liste n'existe pas {bazar[5]}. Cette instruction doit produire une erreur.")
Le premier élément de la liste est : 3.1416
Le troisième élément de la liste est : 154
Le dernier élément de la liste est : dessert
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
Input In [12], in <cell line: 5>()
3 print(f"Le troisième élément de la liste est : {bazar[2]}")
4 print(f"Le dernier élément de la liste est : {bazar[4]}")
----> 5 print(f"Le sixième élément de la liste n'existe pas {bazar[5]}. Cette instruction doit produire une erreur.")
IndexError: list index out of range
La dernière instruction de ce programme produit une erreur. En effet,
elle contient un accès au sixième élément de la liste : bazar[5]. Or
cet élément n’existe pas puisque la liste n’en comporte que cinq.
La valeur de la position fournie lors de l’accès à un élément peut être négative. Dans ce cas, l’accès aux éléments s’effectue à partir de la fin de la liste. Le dernier élément figure alors à la position -1, l’avant-dernier élément à la position -2, etc.
bazar = [3.1416, 25, 154, "fromage", "dessert"]
print(f"L'élément de position -1 est : {bazar[-1]}")
print(f"L'élément de position -5 est : {bazar[-5]}")
L'élément de position -1 est : dessert
L'élément de position -5 est : 3.1416
6.5. Accès à une sous-liste (« list slicing »)
En Python, une sous-liste (on dit aussi une « tranche » de liste) est une sous-séquence de ses éléments, qui débute à partir d’une position de début comprise, et qui se termine à une position de fin non comprise. La syntaxe générale d’accès à une sous-liste est la suivante :
id_liste[pos_deb:pos_fin]
où id_liste est la variable référençant la liste, pos_deb est la
position du premier élément de la sous-liste et pos_fin est la
position du premier élément non compris dans la sous-liste. Les éléments
composant la sous-liste sont donc ceux compris entre la position
pos_deb et la position pos_fin-1.
bazar = [3.1416, 25, 154, "fromage", "dessert"]
print(f"Premier exemple de slicing : {bazar[1:3]}")
print(f"Deuxième exemple de slicing : {bazar[-3:-1]}")
print(f"Troisième exemple de slicing : {bazar[1:-1]}")
Premier exemple de slicing : [25, 154]
Deuxième exemple de slicing : [154, 'fromage']
Troisième exemple de slicing : [25, 154, 'fromage']
Il est possible d’omettre la position pos_fin. Dans ce cas, la
sous-liste contient tous les éléments à partir de la position
pos_deb jusqu’à la fin de la liste.
bazar = [3.1416, 25, 154, "fromage", "dessert"]
print(f"bazar[3:] = {bazar[3:]}")
print(f"bazar[-4:] = {bazar[-4:]}")
bazar[3:] = ['fromage', 'dessert']
bazar[-4:] = [25, 154, 'fromage', 'dessert']
Il est possible d’omettre la position pos_deb. Dans ce cas, la
sous-liste contient tous les éléments à partir du début de la liste
jusqu’à l’élément de rang pos_fin-1.
bazar = [3.1416, 25, 154, "fromage", "dessert"]
print(f"bazar[:3] = {bazar[:3]}")
print(f"bazar[:-3] = {bazar[:-3]}")
bazar[:3] = [3.1416, 25, 154]
bazar[:-3] = [3.1416, 25]
Dans les exemples précédents, tous les éléments des sous-listes sont adjacents dans la liste initiale (i.e., ils sont stockés les uns à côté des autres). Il est possible d’extraire une sous-liste dont les éléments ne sont pas adjacents dans la liste initiale. On parle alors de « slicing » étendu. Dans ce cas, il faut ajouter entre les crochets un troisième nombre, appelé le pas, correspondant à l’écart qu’il doit y avoir entre les positions des éléments à extraire :
id_liste[pos_deb:pos_fin:pas]
Voici ci-dessous des exemples de « slicing » étendu :
alphabet = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
print(f"Extraction de la position 2 à la position 15 comprises, de 2 en 2 : alphabet[2:16:2] = {alphabet[2:16:2]}.")
print(f"Extraction de la position 0 à la position 25 comprises, de 4 en 4 : alphabet[0:26:4] = {alphabet[0:26:4]}.")
Extraction de la position 2 à la position 15, de 2 en 2 : alphabet[2:16:2] = ['c', 'e', 'g', 'i', 'k', 'm', 'o'].
Extraction de la position 0 à la position 25, de 4 en 4 : alphabet[0:26:4] = ['a', 'e', 'i', 'm', 'q', 'u', 'y'].
La valeur de pas peut-être négative. L’extraction s’effectue alors
de droite à gauche à partir de pos_deb jusqu’à pos_fin+1. Dans
ce cas, il faut impérativement que pos_deb soit strictement
supérieure à pos_fin sous peine d’avoir un résultat vide.
alphabet = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
print(f"Extraction de la position 20 à la position 5 comprises, de -2 en -2 : alphabet[20:4:-2] = {alphabet[20:4:-2]}.")
print(f"Extraction de la position 5 à la position 20 comprises, de -2 en -2 : alphabet[5:21:-2] = {alphabet[5:21:-2]}.")
Extraction de la position 20 à la position 5 comprises, de -2 en -2 : alphabet[20:4:-2] = ['u', 's', 'q', 'o', 'm', 'k', 'i', 'g'].
Extraction de la position 5 à la position 20 comprises, de -2 en -2 : alphabet[5:21:-2] = [].
Les valeurs de pos_deb et pos_fin peuvent être omises, comme
l’illustrent les exemples ci-dessous.
alphabet = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
print(f"alphabet[:7:2] = {alphabet[:7:2]}.")
print(f"alphabet[3::2] = {alphabet[3::2]}.")
print(f"alphabet[:3:-2] = {alphabet[:3:-2]}.")
print(f"alphabet[7::-2] = {alphabet[7::-2]}.")
print(f"alphabet[::-1] = {alphabet[::-1]}.")
alphabet[:7:2] = ['a', 'c', 'e', 'g'].
alphabet[3::2] = ['d', 'f', 'h', 'j', 'l', 'n', 'p', 'r', 't', 'v', 'x', 'z'].
alphabet[:3:-2] = ['z', 'x', 'v', 't', 'r', 'p', 'n', 'l', 'j', 'h', 'f'].
alphabet[7::-2] = ['h', 'f', 'd', 'b'].
alphabet[::-1] = ['z', 'y', 'x', 'w', 'v', 'u', 't', 's', 'r', 'q', 'p', 'o', 'n', 'm', 'l', 'k', 'j', 'i', 'h', 'g', 'f', 'e', 'd', 'c', 'b', 'a'].
Notons que le dernier exemple alphabet[::-1] est particulièrement
intéressant. La valeur de pas est de -1, donc les caractères
extraits seront adjacents. Comme il s’agit d’une valeur négative,
l’extraction se fait de droite à gauche en commençant par la fin de la
liste (puisque pos_deb est omise) jusqu’au début de la liste
(puisque pos_fin est omise). On extrait donc tous les caractères
situés de la fin de la liste jusqu’à son début : cela revient tout
simplement à inverser la liste !
Ajoutons pour terminer que toutes les opérations de « slicing » présentées ici sur les listes sont utilisables également sur les chaînes pour extraire des sous-chaînes.
6.6. Opérations, fonctions et instructions usuelles sur les listes
6.6.1. Taille d’une liste : la fonction len()
La taille d’une liste est le nombre d’élements qu’elle contient. La fonction len() :
prend en paramètre une liste
retourne en résultat un nombre entier égal à la taille de cette liste.
bazar = [3.1416, 25, 154, "fromage", "dessert"]
alphabet = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
print(f"La taille de la liste bazar est : {len(bazar)}")
print(f"La taille de la liste alphabet est : {len(alphabet)}")
La taille de la liste bazar est : 5
La taille de la liste alphabet est : 26
6.6.2. Modification d’un élément existant
Un élément d’une liste peut être modifié à l’aide d’une simple opération d’affectation. La syntaxe est la suivante :
id_liste[pos] = valeur
où :
id_listeest l’identifiant de la listeposest la position occupée par l’élément à modifiervaleurest la nouvelle valeur de l’élément
bazar = [3.1416, 25, 154, "fromage", "dessert"]
print(f"Liste bazar avant modification : {bazar}")
bazar[2] = 'bonjour'
bazar[1] += 3
print(f"Liste bazar après modification : {bazar}")
Liste bazar avant modification : [3.1416, 25, 154, 'fromage', 'dessert']
Liste bazar après modification : [3.1416, 28, 'bonjour', 'fromage', 'dessert']
6.6.3. Suppression d’élément(s) : l’instruction del
L’instruction del permet de supprimer un élément ou une sous-liste dans une liste existante. Deux syntaxes sont possibles :
del id_liste[pos]
qui va supprimer de la liste id_liste l’élément situé à la position
pos;
del id_liste[pos_deb:pos_fin]
qui va supprimer de la liste id_liste la sous-liste comprise entre
les positions pos_deb et pos_fin-1.
bazar = [3.1416, 25, 154, "fromage", "dessert"]
print(f"Liste bazar avant première suppression : {bazar}")
del bazar[2]
print(f"Liste bazar après première suppression : {bazar}")
del bazar[1:3]
print(f"Liste bazar après deuxième suppression : {bazar}")
Liste bazar avant première suppression : [3.1416, 25, 154, 'fromage', 'dessert']
Liste bazar après première suppression : [3.1416, 25, 'fromage', 'dessert']
Liste bazar après deuxième suppression : [3.1416, 'dessert']
6.6.4. Concaténation de listes : l’opérateur +
L’opérateur + permet de mettre bout à bout deux listes pour en construire une troisième. C’est ce qu’on appelle la concaténation de listes.
debut = [1, 2]
fin = [3, 4]
total = debut + fin
print(total)
[1, 2, 3, 4]
Il permet également d’ajouter un nouvel élément soit en début de liste :
id_liste = [nouveau] + id_liste
soit en fin de liste :
id_liste = id_liste + [nouveau]
ou bien :
id_liste += [nouveau]
liste = ['B', 'C']
liste = liste + ['D']
liste = ['A'] + liste
print(liste)
['A', 'B', 'C', 'D']
6.6.5. Copie de liste : la fonction list()
Une liste étant un objet « muable », une simple affectation ne suffit pas à en faire une copie. Considérons l’exemple ci-dessous :
maliste = [1, 3, 5, 7, 9, 11] # Création d'une liste initiale
lacopie = maliste # Tentative de copie de la liste initiale par simple affectation
maliste[0] = -1 # Modification de la liste initiale
lacopie[5] = -11 # Modification de la copie
print(f"La liste initiale est {maliste} et la copie est {lacopie}.")
La liste initiale est [-1, 3, 5, 7, 9, -11] et la copie est [-1, 3, 5, 7, 9, -11].
On peut constater lors de l’exécution de ce programme que les contenus
finaux des variables maliste et lacopie sont identiques
(cf. dernière instruction d’affichage). Cela signifie que l’affectation
lacopie = maliste n’a pas créé de copie de la liste. En fait, après
cette affectation les deux variables maliste et lacopie
référencent le même objet liste [1, 3, 5, 7, 9, 11] (cf. schéma
ci-dessous). Les deux instructions maliste[0] = -1 et
lacopie[5] = -11 modifient donc un seul et même objet, même si cet
objet est référencé par deux variables différentes.
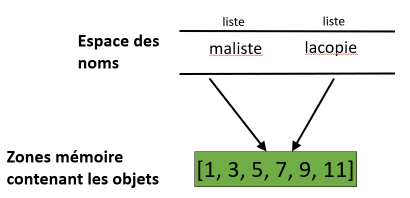
Affectation de liste
La fonction list() est une fonction prédéfinie de Python qui prend en paramètre un objet itérable (chaîne, séquence produite avec range(), liste, etc), et qui crée une liste à partir de cet objet itérable. Elle peut être utilisée pour copier une liste, comme dans l’exemple ci-dessous :
maliste = [1, 3, 5, 7, 9, 11] # Création d'une liste initiale
lacopie = list(maliste) # Création d'une seconde liste à partir de la liste initiale (équivalent à une copie de la liste initiale)
maliste[0] = -1 # Modification de la liste initiale
lacopie[5] = -11 # Modification de la copie
print(f"La liste initiale est {maliste} et la copie est {lacopie}.")
La liste initiale est [-1, 3, 5, 7, 9, 11] et la copie est [1, 3, 5, 7, 9, -11].
Cette fois-ci, l’instruction lacopie = list(maliste) crée une copie
de la liste [1, 3, 5, 7, 9, 11]. Il y a donc deux copies de la
liste, l’une référencée par la variable maliste et l’autre par la
variable lacopie (cf. schéma ci-dessous). L’instruction
maliste[0] = -1 modifie la liste référencée par maliste alors
que l’instruction lacopie[5] = -11 modifie celle référencée par
lacopie. Lors de l’affichage final, les contenus des deux variables
sont donc logiquement différents.
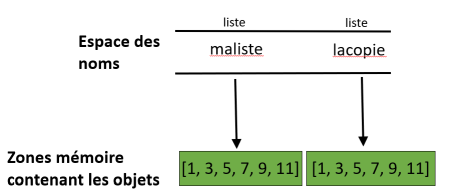
Affectation de liste bis
6.7. Méthodes usuelles sur les listes
En Python, une liste est un objet sur lequel on peut appliquer des méthodes (la programmation objet sera abordée en licence 2). Une méthode est une sorte de fonction ou d’instruction qui va agir sur un objet et retourner ou pas une valeur en résultat. La syntaxe générale d’application d’une méthode à un objet est la suivante :
objet.methode(paramètres)
où :
objetest l’objet ou la variable référençant l’objet sur lequel s’applique la méthodemethodeest le nom de la méthode appliquéeparamètresest l’énumération des valeurs ou variables passées en paramètres de la méthode.
6.7.1. Ajout d’un élément en fin de liste : la méthode append()
La méthode append() prend en paramètre un élément à ajouter à une liste. Elle ajoute cette élément à la fin de la liste et ne retourne aucune valeur. Elle peut donc être utilisée comme une instruction.
liste = ['A', 'B']
liste.append('C')
print(liste)
['A', 'B', 'C']
6.7.2. Extension d’une liste : la méthode extend()
La méthode extend() s’applique à une liste initiale et prend en paramètre une seconde liste. Elle ajoute cette seconde liste à la fin de la liste initiale (ce qui revient à concaténer les deux listes). Elle ne retourne aucune valeur et peut être utilisée comme une instruction.
liste = ['A', 'B']
liste.extend(['C', 'D'])
print(liste)
['A', 'B', 'C', 'D']
6.7.3. Insertion d’un élément à une position précise dans une liste : la méthode insert()
La méthode insert() prend en paramètres :
un nombre entier correspondant à une position dans la liste
un élément à ajouter à la liste
et ajoute l’élément dans la liste, à la position indiquée en paramètre. Elle ne retourne aucune valeur et peut être utilisée comme une instruction. Si la position est égale à 0, l’insertion de l’élément se fait au début de la liste. Si la position correspond à la longueur de la liste, l’insertion s’effectue en fin de liste.
liste = ['B', 'D']
liste.insert(0, 'A')
print(liste)
liste.insert(2, 'C')
print(liste)
liste.insert(len(liste), 'E')
print(liste)
['A', 'B', 'D']
['A', 'B', 'C', 'D']
['A', 'B', 'C', 'D', 'E']
6.7.4. Suppression d’un élément dans une liste : les méthodes remove() et pop()
La méthode remove() prend en paramètre l’élément à supprimer de la liste et supprime de la liste la première occurrence de cet élément. Elle ne retourne aucune valeur et peut être utilisée comme une instruction. Si l’élément passé en paramètre ne figure pas dans la liste, une exception est levée et un message d’erreur s’affiche. La notion d’exception sera vue en licence 2.
liste = ['A', 'B', 'C', 'B', 'D', 'B']
liste.remove('B')
print(liste)
liste.remove('C')
print(liste)
liste.remove('C')
['A', 'C', 'B', 'D', 'B']
['A', 'B', 'D', 'B']
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Input In [24], in <cell line: 6>()
4 liste.remove('C')
5 print(liste)
----> 6 liste.remove('C')
ValueError: list.remove(x): x not in list
La méthode pop() prend en paramètre la position de l’élément à supprimer, supprime cet élément de la liste et retourne ce même élément en résultat. Si la position passée en paramètre n’est pas valide, une exception est levée et un message d’erreur s’affiche. Si aucun paramètre n’est fourni à la méthode, elle supprime et retourne l’élément situé en première position.
liste = ['A', 'B', 'C', 'B', 'D', 'B']
print(f"Liste initiale : {liste}.")
eltpos4 = liste.pop(4)
print(f"Voici la liste après suppression de l'élément {eltpos4} situé à la position 4 : {liste}.")
premier = liste.pop(0)
print(f"Voici la liste après suppression de l'élément {premier} situé en tête de la liste : {liste}.")
premier = liste.pop()
print(f"Voici la liste après suppression de l'élément {premier} situé en tête de la liste : {liste}.")
eltpos8 = liste.pop(8)
print(f"Voici la liste après suppression de l'élément {eltpos8} situé à la position 8 : {liste}.")
Liste initiale : ['A', 'B', 'C', 'B', 'D', 'B'].
Voici la liste après suppression de l'élément D situé à la position 4 : ['A', 'B', 'C', 'B', 'B'].
Voici la liste après suppression de l'élément A situé en tête de la liste : ['B', 'C', 'B', 'B'].
Voici la liste après suppression de l'élément B situé en tête de la liste : ['B', 'C', 'B'].
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
Input In [4], in <cell line: 9>()
7 premier = liste.pop()
8 print(f"Voici la liste après suppression de l'élément {premier} situé en tête de la liste : {liste}.")
----> 9 eltpos8 = liste.pop(8)
10 print(f"Voici la liste après suppression de l'élément {eltpos8} situé à la position 8 : {liste}.")
IndexError: pop index out of range
6.7.5. Position d’un élément dans une liste : la méthode index()
La méthode index() prend en paramètre un élément et retourne la position de la première occurrence de cet élément dans la liste. Une exception est levée si l’élément ne figure pas dans la liste.
liste = ['A', 'B', 'C', 'B', 'D', 'B']
print(liste.index('C'))
print(liste.index('B'))
print(liste.index('E'))
2
1
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Input In [25], in <cell line: 4>()
2 print(liste.index('C'))
3 print(liste.index('B'))
----> 4 print(liste.index('E'))
ValueError: 'E' is not in list
6.7.6. Comptage du nombre d’occurrences d’un élément : la méthode count()
La méthode count() prend en paramètre un élément et retourne le nombre d’occurrences de cet élément dans la liste.
liste = ['A', 'B', 'C', 'B', 'D', 'B']
nb_C = liste.count('C')
nb_B = liste.count('B')
nb_E = liste.count('E')
print(f"Dans la liste, la lettre C apparaît {nb_C} fois, la lettre B {nb_B} fois et la lettre E {nb_E} fois.")
Dans la liste, la lettre C apparaît 1 fois, la lettre B 3 fois et la lettre E 0 fois.
6.7.7. Tri des éléments d’une liste : la méthode sort()
La méthode sort() permet de trier les éléments d’une liste. Elle ne retourne aucune valeur et peut être utilisée comme une instruction. La nature du tri dépend du type des éléments. Si ceux-ci sont numériques, le tri le sera également.
liste_num = [126, 6, 6148, 34]
liste_num.sort()
print(f"Exemple de liste numérique triée : {liste_num}")
Exemple de liste numérique triée : [6, 34, 126, 6148]
Si les éléments sont textuels (chaînes), le tri sera lexicographique (i.e. à peu près équivalent au tri alphabétique).
liste_lettre = ['A', 'B', 'C', 'B', 'D', 'B']
liste_lettre.sort()
print(f"Exemple de liste de lettres triée : {liste_lettre}")
liste_ch = ['126', '6', '6148', '34']
liste_ch.sort()
print(f"Exemple de liste de chaînes triée : {liste_ch}")
Exemple de liste de lettres triée : ['A', 'B', 'B', 'B', 'C', 'D']
Exemple de liste de chaînes triée : ['126', '34', '6', '6148']
L’application de cette méthode sur une liste mixte (i.e. une liste contenant des éléments de types différents), provoque la levée d’une exception puisque le tri n’a pas de sens dans ce cas.
melange = [3.1416, 'fromage', 154, 25, 'dessert', 'fromage']
melange.sort()
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Input In [5], in <cell line: 2>()
1 melange = [3.1416, 'fromage', 154, 25, 'dessert', 'fromage']
----> 2 melange.sort()
TypeError: '<' not supported between instances of 'str' and 'float'
Par défaut, le tri s’effectue dans l’ordre croissant. Pour réaliser un
tri décroissant, il faut appliquer la méthode sort() avec la valeur
True pour le paramètre reverse.
liste = [126, 6, 6148, 34]
liste.sort(reverse=True)
print(f"Exemple de tri décroissant : {liste}.")
Exemple de tri décroissant : [6148, 126, 34, 6].
Pour personnaliser encore plus les critères du tri, il est également
possible d’ajouter d’autres paramètres à la méthode sort() comme par
exemple :
cmp: la fonction de comparaison entre deux éléments (fonction avec deux paramètres)key: la fonction calculant la clé de tri pour chaque élément. Le tri s’effectue alors selon les clés des éléments.
Supposons par exemple qu’on ait besoin de trier une liste de mots
(chaînes) en ordre croissant de leurs longueurs (i.e. de leurs nombres
de lettres). La fonction qui calcule la longueur d’une chaîne est
len(). Pour trier en fonction de la longueur, il faut alors
appliquer la méthode sort() avec len() comme clé de tri,
c’est-à-dire avec la valeur len pour le paramètre key.
liste_mots = ['orange', 'poire', 'pomme', 'framboise', 'kiwi', 'cerise']
liste_mots.sort(key=len)
print(f"Exemple de tri de chaînes selon la longueur : {liste_mots}")
Exemple de tri de chaînes selon la longueur : ['kiwi', 'poire', 'pomme', 'orange', 'cerise', 'framboise']
Notons à travers cet exemple que si deux chaînes de la liste ont même
longueur, elles n’apparaissent pas en ordre alphabétique dans le
résultat. Cela est normal puisque la clé de tri a été remplacée par la
fonction len() et que l’ordre lexicographique ne s’applique plus.
6.7.8. Inversion d’une liste : la méthode reverse()
La méthode reverse() permet d’inverser l’ordre des éléments d’une liste. Elle ne retourne aucune valeur et peut être utilisée comme une instruction.
liste_vrac = ['orange', 78, 'pomme', 'framboise', True, 2.36]
liste_vrac.reverse()
print(f"Exemple de liste inversée : {liste_vrac}")
Exemple de liste inversée : [2.36, True, 'framboise', 'pomme', 78, 'orange']
6.7.9. Transformation d’une chaîne en une liste de chaînes : la méthode split()
La méthode split() s’applique à une chaîne de caractères et permet de découper cette chaîne en plusieurs sous-chaînes. Le découpage s’effectue grâce à un élément séparateur qui est constitué par défaut d’une suite quelconque d’espaces. La méthode retourne la liste des sous-chaînes obtenues par découpage. Cette méthode peut être utilisée pour extraire la liste des mots contenus dans une phrase, comme le montre l’exemple suivant.
laphrase = "Youpidou la ribambelle"
lesmots = laphrase.split()
print(lesmots)
['Youpidou', 'la', 'ribambelle']
Il est possible de définir élément séparateur autre que la suite
quelconque d’espaces. Dans ce cas, il faut l’indiquer en paramètre de la
méthode. L’exemple suivant décompose une chaîne en utilisant le tiret
'-' comme élément séparateur.
ph = "251-964-89523-74"
lm = ph.split('-')
print(lm)
['251', '964', '89523', '74']
On peut également donner en second paramètre un nombre correspondant à l’indice maximal de la liste à retourner (0 pour une liste avec un seul élément, 1 pour une liste de 2 éléments, etc).
ph = "251-964-89523-74"
lm2 = ph.split('-', 1)
print(lm2)
['251', '964-89523-74']
ph = "251-964-89523-74"
lm3 = ph.split('-', 2)
print(lm3)
['251', '964', '89523-74']
6.7.10. Copie d’une liste : la méthode copy()
La méthode copy() s’applique à une liste et permet de créer une copie de cette liste, comme le montre l’exemple suivant.
maliste = [1, 3, 5, 7, 9, 11] # Création d'une liste initiale
lacopie = maliste.copy() # Création d'une copie de la liste initiale
maliste[0] = -1 # Modification de la liste initiale
lacopie[5] = -11 # Modification de la copie
print(f"La liste initiale est {maliste} et la copie est {lacopie}.")
La liste initiale est [-1, 3, 5, 7, 9, 11] et la copie est [1, 3, 5, 7, 9, -11].
6.8. Opérateur d’appartenance à une liste
L’opérateur in permet de tester si un élément appartient ou non à une liste. Sa syntaxe est la suivante :
element in id_liste
où id_liste est l’identifiant de la liste et element l’élément
ou la variable référençant l’élément. L’opérateur retourne True si
l’élément figure dans la liste et False sinon. Si l’élément à tester
est une chaîne, la « casse », c’est-à-dire la différence entre majuscule
et minuscule, sera prise en compte.
liste_vrac = ['orange', 78, 'pomme', 'framboise', True, 2.36]
print(f"78 appartient-il à la liste ? Réponse : {78 in liste_vrac}")
print(f"framboise appartient-elle à la liste ? Réponse : {'framboise' in liste_vrac}")
print(f"Pomme appartient-elle à la liste ? Réponse : {'Pomme' in liste_vrac}")
78 appartient-il à la liste ? Réponse : True
framboise appartient-elle à la liste ? Réponse : True
Pomme appartient-elle à la liste ? Réponse : False
6.9. Parcours d’une liste
Une liste est une séquence, et est de ce fait un objet « itérable ».
Cela signifie qu’on peut parcourir un à un ses éléments à l’aide d’une
boucle for pour leur appliquer un traitement. Il existe trois
manières d’effectuer un parcours complet d’une liste :
le parcours par élément
le parcours par indice
le parcours par indice et élément.
6.9.1. Parcours par élément
La syntaxe d’une boucle for effectuant un parcours par élément d’une
liste est la suivante :
for var_elem in id_liste:
bloc_instructions
où :
var_elemest une variableid_listeest l’identifiant de la liste à parcourirbloc_instructionsest un bloc d’instructions (attention à l’indentation !!).
Littéralement : « Pour chaque élément var_elem contenu dans la liste
id_liste effectuer les instructions de bloc_instructions ». La
variable var_elem va prendre successivement tous les éléments de la
liste id_liste, du premier au dernier. Pour chaque valeur de
var_elem (i.e. chaque élément de la liste), bloc_instructions
est exécuté. Le type de la variable var_elem change en fonction de
ceux des éléments de la liste (le typage est dynamique).
Voici un premier exemple de programme qui parcourt une liste par élément, en affichant chacun des éléments à l’écran.
bazar = [3.1416, 25, 154, 'fromage', 'dessert']
for elt in bazar:
print(elt)
3.1416
25
154
fromage
dessert
Voici un second exemple de programme qui parcourt une liste élément par élément, en affichant à l’écran chaque élément ainsi que son type.
bazar = [3.1416, 25, 154, 'fromage', 'dessert']
for elt in bazar:
print(f"La liste contient {elt} qui est de type {type(elt)}.")
La liste contient 3.1416 qui est de type <class 'float'>.
La liste contient 25 qui est de type <class 'int'>.
La liste contient 154 qui est de type <class 'int'>.
La liste contient fromage qui est de type <class 'str'>.
La liste contient dessert qui est de type <class 'str'>.
6.9.2. Parcours par indice (ou parcours par position)
Le principe du parcours par indice est de parcourir une liste en
utilisant les indices (i.e. les positions) de ses éléments (et pas les
éléments eux-mêmes). La syntaxe d’une boucle for effectuant un
parcours par indice d’une liste est la suivante :
for ind in range(len(id_liste)):
bloc_instructions
où :
indest une variableid_listeest l’identifiant de la liste à parcourirrange(len(id_liste))permet de générer la séquence de tous les indices des éléments de la listeid_liste:0, 1,..., len(id_liste)-1.
La variable ind va prendre successivement toutes les valeurs des
indices de la liste, en commençant par 0 jusqu’à
len(id_liste)-1. Pour chaque valeur de ind, le bloc
bloc_instructions est exécuté.
Voici un premier exemple de programme qui parcourt une liste par indice, en affichant chacun des éléments à l’écran.
bazar = [3.1416, 25, 154, 'fromage', 'dessert']
for i in range(len(bazar)):
print(bazar[i])
3.1416
25
154
fromage
dessert
Dans cet exemple, len(bazar) retourne le nombre 5, la séquence
de nombres générée par range(len(bazar)) est donc :
0, 1, 2, 3, 4. Les valeurs successives de la variable i seront
donc 0, puis 1, 2, 3, et enfin 4.
Voici un second exemple de programme qui parcourt une liste par indice, en affichant à l’écran chaque élément ainsi que son type.
bazar = [3.1416, 25, 154, 'fromage', 'dessert']
for i in range(len(bazar)):
print(f"La liste contient {bazar[i]} qui est de type {type(bazar[i])}.")
La liste contient 3.1416 qui est de type <class 'float'>.
La liste contient 25 qui est de type <class 'int'>.
La liste contient 154 qui est de type <class 'int'>.
La liste contient fromage qui est de type <class 'str'>.
La liste contient dessert qui est de type <class 'str'>.
6.9.3. Parcours par indice et élément
Ce parcours permet de parcourir un par un les éléments d’une liste, en
disposant pour chaque élément de son indice, mais également de sa
valeur. La syntaxe d’une boucle for effectuant un parcours par
indice et élément est la suivante :
for ind, val in enumerate(id_liste):
bloc_instructions
où :
indetvalsont des variables représentant respectivement les indices et les valeurs des éléments de la listeid_listeest l’identifiant de la liste à parcourirenumerate(id_liste)permet de générer la séquence de tous les couples (indice, valeur) de la listeid_liste.
Les variables ind et val vont prendre successivement toutes les
valeurs des indices (ind) et des éléments (val) de la liste.
Pour chaque binôme de valeurs ind et val, le bloc
bloc_instructions est exécuté. Voici un exemple de programme
parcourant une liste par indice et élément. Pour chaque élément de la
liste, le programme affiche son indice suivi de sa valeur.
classement = ['Arthur', 'Barnabé', 'Côme', 'Damien', 'Emile']
for ind, val in enumerate(classement):
print(f"L'élément situé au rang {ind} est {val}.")
L'élément situé au rang 0 est Arthur.
L'élément situé au rang 1 est Barnabé.
L'élément situé au rang 2 est Côme.
L'élément situé au rang 3 est Damien.
L'élément situé au rang 4 est Emile.
6.9.4. Parcours partiel
Le parcours par indice vu précédemment permet de choisir les indices des
éléments à parcourir, ce qui n’est pas le cas du parcours par élément.
On peut donc l’utiliser pour effectuer un parcours partiel d’une liste.
La syntaxe d’une boucle for effectuant un parcours par indice
partiel d’une liste est la suivante :
for ind in range(pos_debut, pos_fin, pas):
bloc_instructions
où range(pos_debut, pos_fin, pas) permet de générer la séquence des
indices des éléments à parcourir. Attention : toutes les valeurs de
cette séquence doivent correspondre effectivement à des indices
d’éléments figurant dans la liste, sous peine d’entraîner une erreur à
l’exécution.
Voici ci-dessous trois exemples de parcours par indice partiels d’une liste.
bazar = [3.1416, 25, 154, 'fromage', 'dessert']
for i in range(1, 4):
print(f"La liste contient à l'indice {i} l'élément {bazar[i]} qui est de type {type(bazar[i])}.")
La liste contient à l'indice 1 l'élément 25 qui est de type <class 'int'>.
La liste contient à l'indice 2 l'élément 154 qui est de type <class 'int'>.
La liste contient à l'indice 3 l'élément fromage qui est de type <class 'str'>.
bazar = [3.1416, 25, 154, 'fromage', 'dessert']
for i in range(1, 6):
print(f"La liste contient à l'indice {i} l'élément {bazar[i]} qui est de type {type(bazar[i])}.")
La liste contient à l'indice 1 l'élément 25 qui est de type <class 'int'>.
La liste contient à l'indice 2 l'élément 154 qui est de type <class 'int'>.
La liste contient à l'indice 3 l'élément fromage qui est de type <class 'str'>.
La liste contient à l'indice 4 l'élément dessert qui est de type <class 'str'>.
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
Input In [16], in <cell line: 2>()
1 bazar = [3.1416, 25, 154, 'fromage', 'dessert']
2 for i in range(1, 6):
----> 3 print(f"La liste contient à l'indice {i} l'élément {bazar[i]} qui est de type {type(bazar[i])}.")
IndexError: list index out of range
bazar = [3.1416, 25, 154, 'fromage', 'dessert']
for i in range(0, len(bazar), 2):
print(f"La liste contient à l'indice {i} l'élément {bazar[i]} qui est de type {type(bazar[i])}.")
La liste contient à l'indice 0 l'élément 3.1416 qui est de type <class 'float'>.
La liste contient à l'indice 2 l'élément 154 qui est de type <class 'int'>.
La liste contient à l'indice 4 l'élément dessert qui est de type <class 'str'>.
6.10. Compréhension de liste
La compréhension de liste est un mécanisme du langage Python permettant de créer une liste, non pas en lui ajoutant ses éléments un par un, mais en précisant les caractéristiques partagées par tous ses éléments. On peut la comparer à une définition en intension d’un ensemble en mathématique, telle que par exemple : \(S = \{x / x \in \mathbb{N}, x^2 < 100 \}\).
Il existe deux types de compréhension de liste : la compréhension sans conditionnelle et la compréhension avec conditionnelle.
6.10.1. Compréhension sans conditionnelle
La syntaxe générale de la compréhension de liste sans conditionnelle est la suivante :
[exp for elem in seq]
où :
expest une expression qui va permettre de générer tous les éléments de la listeelemest une variableseqest une séquence de valeurs (liste, résultat d’une fonction range(), etc).
Le résultat est une liste contenant un élément dont la valeur est
obtenue par évaluation de l’expression exp, pour chaque exécution de
la boucle for. Par exemple, [elt for elt in range(5)] retourne
la liste [0, 1, 2, 3, 4].
liste = [elt for elt in range(5)]
print(liste)
[0, 1, 2, 3, 4]
[elt*3 for elt in range(5)] retourne la liste [0, 3, 6, 9, 12].
liste = [elt*3 for elt in range(5)]
print(liste)
[0, 3, 6, 9, 12]
Le programme suivant mémorise une liste de mots, et utilise la compréhension pour calculer la liste des longueurs des mots.
liste_mots = ['orange', 'poire', 'pomme', 'framboise', 'kiwi', 'cerise']
liste_longueurs = [len(mot) for mot in liste_mots]
print(liste_longueurs)
[6, 5, 5, 9, 4, 6]
Le programme suivant crée une liste de 20 nombres entiers aléatoires entre 1 et 50.
from random import randint
alea = [randint(1, 50) for cpt in range(20)]
print(alea)
[16, 36, 26, 7, 34, 48, 29, 24, 11, 25, 1, 35, 40, 34, 33, 36, 42, 17, 3, 15]
Enfin, le programme suivant permet de convertir tous les éléments d’une liste en chaînes de caractères.
bazar = [3.1416, 25, 154, 'fromage', 'dessert']
bazar = [str(elt) for elt in bazar]
print(bazar)
['3.1416', '25', '154', 'fromage', 'dessert']
6.10.2. Compréhension avec conditionnelle
La syntaxe générale de la compréhension de liste avec conditionnelle est la suivante :
[exp for elem in seq if exp_cond]
où exp_cond est une expression conditionnelle que doivent vérifier
tous les éléments de la liste retournée.
Le résultat est une liste contenant un élément dont la valeur est
obtenue par évaluation de l’expression exp, vérifiant la condition
exp_cond, pour chaque exécution de la boucle for. Par exemple,
[elt for elt in range(15) if elt%2==0] retourne la liste
[0, 2, 4, 6, 8, 10, 12, 14].
liste = [elt for elt in range(15) if elt%2==0]
print(liste)
[0, 2, 4, 6, 8, 10, 12, 14]
Le programme suivant permet d’extraire les chaînes de caractères et les nombres entiers d’une liste.
bazar = [3.1416, 25, 154, 'fromage', 'dessert']
chaines = [elt for elt in bazar if type(elt)==str]
nombres = [elt for elt in bazar if type(elt)==float or type(elt)==int]
print(f"Les chaînes sont {chaines} et les nombres sont {nombres}.")
Les chaînes sont ['fromage', 'dessert'] et les nombres sont [3.1416, 25, 154].
En conclusion, nous pouvons dire que la compréhension de liste est très utile lorsqu’il s’agit de créer des listes dont les élément ont des caractéristiques communes. Dans ce cas précis, elle n’est pas indispensable mais simplifie le travail par la compacité de son code. Pour vous en convaincre, essayez d’écrire les exemples ci-dessus sans utiliser la compréhension !
6.11. Les tuples
Tout comme une liste, un tuple est une séquence ordonnée d’objets de types variés, indexée sur les indices de ses éléments. La différence avec une liste est qu’un tuple est un objet Python « immuable ». Cela signifie que pour modifier une variable référençant un tuple, il faut impérativement réaliser une nouvelle affectation. On ne peut pas effectuer de manipulation entraînant une modification sur un tuple. Les tuples sont donc utiles dans un programme pour mémoriser des données qu’on ne souhaite pas modifier « accidentellement ».
6.11.1. Notation, création
La notation utilisée pour un tuple est quasiment la même que celle d’une liste. La seule différence réside dans l’utilisation de parenthèses à la place des crochets. Voici un programme simple de création de tuples :
tuple1 = ('a', 'b', 5, 2, False, 9.63)
tuple2 = ('lundi', 'mardi', 'mercredi', 'jeudi', 'vendredi', 'samedi', 'dimanche')
print(tuple1)
print(tuple2)
('a', 'b', 5, 2, False, 9.63)
('lundi', 'mardi', 'mercredi', 'jeudi', 'vendredi', 'samedi', 'dimanche')
6.11.2. Manipulation de tuples
Toutes les manipulations de listes vues dans ce chapitre qui n’entraînent pas de modification peuvent être réalisées sur les tuples :
accès aux éléments et « slicing » (avec utilisation des crochets)
fonction
len()pour calculer la tailleopérateur d’appartenance
inopérateurs de concaténation
+et de répétition*position d’un élément
index()comptage du nombre d’occurrences d’un élément
count()parcours avec la boucle
forcompréhension
Les syntaxes de ces manipulations sont exactement les mêmes que pour les
listes, excepté pour la compréhension. Dans ce cas précis, la notation
tuple(..) remplace les crochets, comme le montre l’exemple
ci-dessous.
tuple1 = tuple(elt for elt in range(4))
print(tuple1)
(0, 1, 2, 3)